什么是Socket?
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
TCP连接的端点是由一个IP地址和一个PORT来唯一标识的。IP是用来标识互联网中的一台主机的位置,而PORT是用来标识这台机器上的一个应用程序,IP地址是配置到网卡上的,而PORT是应用程序开启的。
而程序的pid是同一台机器上不同进程或者线程的标识
Socket分类
套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)
套接字工作流程
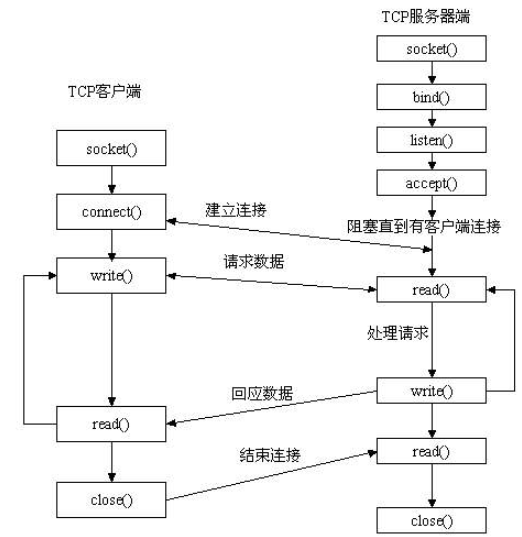
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
Socket模块用法
import socket
socket_server = socket.socket(socket_family,socket_type,protocal=0)
# socket_family 可以是 AF_UNIX 或 AF_INET。
# socket_type 可以是 SOCK_STREAM 或 SOCK_DGRAM。
# protocol 一般不填,默认值为 0。
#获取tcp/ip套接字
tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#获取udp/ip套接字
udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件
基于TCP的套接字编程
tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端
服务端开启
```
import socket
tcpsocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
创建socket对象
tcpsocket.bind(('127.0.0.1', 8080))
把地址绑定到套接字
tcpsocket.listen(5)
监听连接,相当于一个连接池
while True:
# 服务器无限连接循环
conn, addr = tcpsocket.accept()
# 接收客户端连接
print(conn, addr)
while True:
# 通讯循环
msg = conn.recv(1024)
# 对话接收
if len(msg) == 0:
break
print(msg.decode('utf8'), type(msg))
conn.send(msg.upper())
# 对话发送
conn.close()
# 关闭客户端套接字(这是个系统资源占用)
tcpsocket.close()
关闭服务端套接字
<h4 id='title'>客户端开启</h4>
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect_ex(('127.0.0.1', 8080))
connect_ex()出错时返回出错码,而不是抛出异常
flag = True
while flag:
msg = input('请输入》》》').strip()
if len(msg) == 0:
continue
if msg == 'q':
flag = False
client_socket.send(bytes(msg, encoding='utf8'))
feed_back = client_socket.recv(1024)
print(feed_back.decode('utf8'))
client_socket.close()
扩展学习:
TCP的三次握手四次挥手
SYN洪水攻击
服务器高并发情况下会有大量的time_wait状态的优化方法
<h4 id='title'>解决方法</h2>
方法一:
加入一条socket配置,重用ip和端口
phone=socket(AF_INET,SOCK_STREAM)
phone.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加
phone.bind(('127.0.0.1',8080))
方法二:
发现系统存在大量TIME_WAIT状态的连接,通过调整linux内核参数解决,
vi /etc/sysctl.conf
编辑文件,加入以下内容:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
然后执行 /sbin/sysctl -p 让参数生效。
###################################
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout 修改系統默认的 TIMEOUT 时间
<h2 class='h2-title'>基于UDP的套接字编程</h2>
UDP是无链接的,先启动哪一端都不会报错
通常UDP会用在客户端向服务端申请一个比特的信息,如果没有收到答复继续申请。
用到UDP最广的是DNS系统,因为客户端通常只需要发送简短请求,并收到简短恢复,UDP非常适合这种操作。
UDP的限制是一个信息包不超过64KB的数据,通常人们只用UDP发送1KB以下的数据。
<h4 id='title'>服务端开启</h4>
import socket
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
udp_socket.bind(('127.0.0.1', 8080))
while True:
msg, addr = udp_socket.recvfrom(1024)
# addr是一个元组,第一个元素是ip,第二个元素是port
print(msg.decode('utf8'), addr)
udp_socket.sendto(msg.upper(), addr)
<h4 id='title'>客户端开启</h4>
import socket
ip_port = ('127.0.0.1', 8080)
udp_client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
while True:
msg = input("请输入>>>").strip()
if not msg:
continue
udp_client.sendto(bytes(msg, encoding='utf8'), ip_port)
back_msg, addr= udp_client.recvfrom(1024)
print(back_msg.decode('utf8'), addr)
<h2 class='h2-title'>粘包问题</h2>
<h4 id='title'>什么是粘包?</h4>
知识储备:Socket收发消息原理
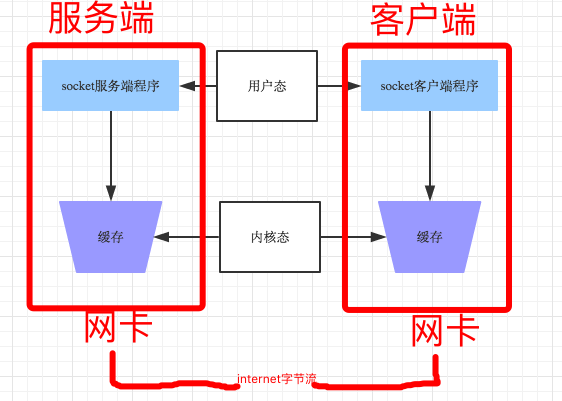
发送端可以是1K1K地发送数据,而接收端的应用程序可以2K2K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据,也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。而UDP是面向消息的协议,```每个UDP段都是一条消息```,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,```TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区```。
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束
所谓粘包问题```主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的```。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法(Nagle,将数据量小并且时间间隔短的数据一次打包发给接收端)把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
- TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
- UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
- tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头,实验略
udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y>x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠
tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在```收到ack时才会清除缓冲区内容```。数据是可靠的,但是会粘包。
<h4 id='title'>会出现粘包的情况</h4>
第一种:发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
第二种:接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
<h4 id='title'>拆包发生的情况</h4>
当发送端缓冲区的长度大于网卡的MTU时,tcp会将这次发送的数据拆成几个数据包发送出去。
<h4 id='title'>send(字节流)和recv(1024)及sendall</h4>
recv里指定的1024意思是从缓存里一次拿出1024个字节的数据
send的字节流是先放入己端缓存,然后由协议控制将缓存内容发往对端,如果待发送的字节流大小大于缓存剩余空间,那么数据丢失,用sendall就会循环调用send,数据不会丢失
<h4 id='title'>TCP粘包制作</h4>
**服务端开启**
from socket import *
import subprocess
ip_port = ('127.0.0.1', 8080)
BUFSIZE = 1024
tcp_server = socket(AF_INET, SOCK_STREAM)
tcp_server.bind(ip_port)
tcp_server.listen(5)
while True:
conn, addr = tcp_server.accept()
print(conn)
while True:
cmd = conn.recv(BUFSIZE)
if len(cmd) == 0:
break
res = subprocess.Popen(
cmd.decode('utf8'),
shell=True,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.PIPE
)
stderr = res.stderr.read()
stdout = res.stdout.read()
conn.send(stderr)
conn.send(stdout)
**TCP客户端制作**
from socket import *
ip_port = ('127.0.0.1', 8080)
BUFSIZE = 1024
tcp_client = socket(AF_INET, SOCK_STREAM)
res = tcp_client.connect_ex(ip_port)
while True:
msg = input("请输入>>>").strip()
if len(msg) == 0:
continue
if msg == 'quit':
break
tcp_client.send(msg.encode('utf-8'))
act_res = tcp_client.recv(BUFSIZE)
print(act_res.decode('gbk'))
<h4 id='title'>解决粘包问题<h4>
为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据。
struct模块 可以把一个类型,如数字,转成固定长度的bytes。
import json,struct
假设通过客户端上传1T:1073741824000的文件a.txt
为避免粘包,必须自定制报头
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值
为了该报头能传送,需要序列化并且转为bytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输
为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节
head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度
客户端开始发送
conn.send(head_len_bytes) #先发报头的长度,4个bytes
conn.send(head_bytes) #再发报头的字节格式
conn.sendall(文件内容) #然后发真实内容的字节格式
服务端开始接收
head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式
x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度
head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式
header=json.loads(json.dumps(header)) #提取报头
最后根据报头的内容提取真实的数据,比如
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)
我们可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个自己足够用了)
发送时:
先发报头长度
再编码报头内容然后发送
最后发真实内容
接收时:
先手报头长度,用struct取出来
根据取出的长度收取报头内容,然后解码,反序列化
从反序列化的结果中取出待取数据的详细信息,然后去取真实的数据内容
第一版服务端开启
import socket,struct,json
import subprocess
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #就是它,在bind前加
phone.bind(('127.0.0.1',8080))
phone.listen(5)
while True:
conn,addr=phone.accept()
while True:
cmd=conn.recv(1024)
if not cmd:break
print('cmd: %s' %cmd)
res=subprocess.Popen(cmd.decode('utf-8'),
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
err=res.stderr.read()
print(err)
if err:
back_msg=err
else:
back_msg=res.stdout.read()
headers={'data_size':len(back_msg)}
head_json=json.dumps(headers)
head_json_bytes=bytes(head_json,encoding='utf-8')
conn.send(struct.pack('i',len(head_json_bytes))) #先发报头的长度
conn.send(head_json_bytes) #再发报头
conn.sendall(back_msg) #在发真实的内容
conn.close()
第一版客户端开启
from socket import *
import struct,json
ip_port=('127.0.0.1',8080)
client=socket(AF_INET,SOCK_STREAM)
client.connect(ip_port)
while True:
cmd=input('>>: ')
if not cmd:continue
client.send(bytes(cmd,encoding='utf-8'))
head=client.recv(4)
head_json_len=struct.unpack('i',head)[0]
head_json=json.loads(client.recv(head_json_len).decode('utf-8'))
data_len=head_json['data_size']
recv_size=0
recv_data=b''
while recv_size < data_len:
recv_data+=client.recv(1024)
recv_size+=len(recv_data)
print(recv_data.decode('utf-8'))
#print(recv_data.decode('gbk')) #windows默认gbk编码