机器学习之Logistic regression
Logistic regression (LR)是一种非常常用判别模型。在实际应用中使用非常广泛。为什么说LR是一种判别模型呢?它与生成式模型有什么区别呢?
一般来说,如果模型是直接对样本本身的分布建模
LR就是典型的概率模型,LR是针对两类问题进行分类。LR使用了sigmoid函数来对后验概率建模。
sigmoid函数具有如下性质:
而LR就是在线性模型基础上加上了一种sigmoid函数,
假定有二分类问题,给定样本
那么对数似然为:
令
有了参数的导数,就可以利用梯度下降法来求解参数
目前为止,讨论的是二类问题。对于多类问题,也是类似的。将每一类的类别标签表示为one-hot的向量形式。而分类函数则为:
其中,
对于
对数似然为:
分别对
有了这个参数的导数就可以采用梯度下降法来求解参数。
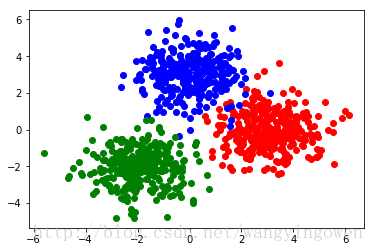
还是采用python来实现,首先用高斯函数生成三类样本
代码
LR的例子:
from scipy.stats import multivariate_normal
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
N=1000;
N_train = 300;
X1=multivariate_normal.rvs(mean=[3,0],cov=[[1,0],[0,1]],size=N)#从均值为[0.3,0.5],方差为[[1,0.5],[0.5,1]]的二元高斯分布中生成10000个样本
T1=np.zeros([N,3]);
T1[:,0]=1.0;
X2=multivariate_normal.rvs(mean=[0,3],cov=[[1,0],[0,1]],size=N)
T2=np.zeros([N,3]);
T2[:,1]=1.0;
X3=multivariate_normal.rvs(mean=[-2,-2],cov=[[1,0],[0,1]],size=N)
T3=np.zeros([N,3]);
T3[:,2]=1.0;
#plt.plot(X1[:,0],X1[:,1],'or',X2[:,0],X2[:,1],'ob',X3[:,0],X3[:,1],'og')
Index1 = np.random.permutation(N)
TrainData1 = X1[Index1[0:N_train],:]
TestData1 = X1[Index1[N_train:N],:]
TrainLabel1 = T1[Index1[0:N_train],:]
TestLabel1 = T1[Index1[N_train:N],:]
Index2 = np.random.permutation(N)
TrainData2 = X2[Index2[0:N_train],:]
TestData2 = X2[Index2[N_train:N],:]
TrainLabel2 = T2[Index2[0:N_train],:]
TestLabel2 = T2[Index2[N_train:N],:]
Index3 = np.random.permutation(N)
TrainData3 = X3[Index3[0:N_train],:]
TestData3 = X3[Index3[N_train:N],:]
TrainLabel3 = T3[Index1[0:N_train],:]
TestLabel3 = T3[Index1[N_train:N],:]
#plt.plot(X1[:,0],X1[:,1],'or',X2[:,0],X2[:,1],'ob',X3[:,0],X3[:,1],'og')
plt.figure()
plt.plot(TrainData1[:,0],TrainData1[:,1],'or',TrainData2[:,0],TrainData2[:,1],'ob',TrainData3[:,0],TrainData3[:,1],'og')
TrainData=np.concatenate((TrainData1,TrainData2,TrainData3));
TrainLabel = np.concatenate((TrainLabel1,TrainLabel2,TrainLabel3));
N_t,d=TrainData.shape
index = np.random.permutation(N_t)
TrainData = TrainData[index,:]
TrainLabel = TrainLabel[index,:]
#plt.figure()
#plt.plot(TrainData[:,0],TrainData[:,1],'or')
#training process;
W = np.random.randn(2,3)
b = np.zeros([1,3])
eta = 0.01
IterNumber = 50000
Label_True = np.argmax(TrainLabel,axis=1)
#训练#
for i in range(IterNumber+1):
Z = np.matmul(TrainData,W)+np.tile(b,[N_t,1])
Y = np.exp(Z)
M = np.sum(Y,axis=1)
Y = np.divide(Y.transpose(),M).transpose() #输出标签#
E = np.sum(np.multiply(TrainLabel,np.log(Y)))
if np.remainder(i,100)==0:
Index = np.argmax(Y,axis=1)
D=(Index==Label_True)
correct = np.sum(D)
print('correct=',correct/N_t)
print(E)
YT=Y-TrainLabel;
deltaW = np.matmul(TrainData.transpose(),YT) / N_t #W的梯度#
deltaB = np.mean(YT,axis=0); #b的梯度#
W = W-eta*deltaW;
b = b-eta*deltaB;
#在测试集上的分类结果#
TestData=np.concatenate((TestData1,TestData2,TestData3));
TestLabel = np.concatenate((TestLabel1,TestLabel2,TestLabel3));
Label_True = np.argmax(TestLabel,axis=1)
N_test,dim=TestData.shape
Z = np.matmul(TestData,W)+np.tile(b,[N_test,1])
Y = np.exp(Z)
M = np.sum(Y,axis=1)
Y = np.divide(Y.transpose(),M).transpose()
Index = np.argmax(Y,axis=1)
D=(Index==Label_True)
correct = np.sum(D)/N_test
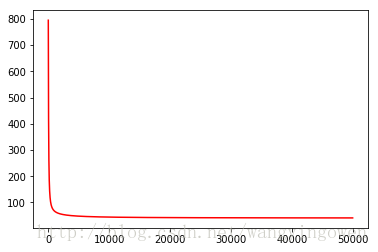
print('correct=',correct)上面for循环过程就是训练过程。下图是能量函数的曲线,可以看出能量是下降的,说明训练过程是收敛的。
现在用tensorflow来实现下LR
LR的tensorflow实现(这里每次迭代都用到了所有样本,可以采用batch的方式):
# -*- coding: utf-8 -*-
""" Created on Sat Nov 25 16:17:35 2017 @author: wangying """
from scipy.stats import multivariate_normal
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import tensorflow as tf
#生成模拟数据
N=1000;
N_train = 300;
X1=multivariate_normal.rvs(mean=[3,0],cov=[[1,0],[0,1]],size=N)#从均值为[0.3,0.5],方差为[[1,0.5],[0.5,1]]的二元高斯分布中生成10000个样本
T1=np.zeros([N,3]);
T1[:,0]=1.0;
X2=multivariate_normal.rvs(mean=[0,3],cov=[[1,0],[0,1]],size=N)
T2=np.zeros([N,3]);
T2[:,1]=1.0;
X3=multivariate_normal.rvs(mean=[-2,-2],cov=[[1,0],[0,1]],size=N)
T3=np.zeros([N,3]);
T3[:,2]=1.0;
#plt.plot(X1[:,0],X1[:,1],'or',X2[:,0],X2[:,1],'ob',X3[:,0],X3[:,1],'og')
Index1 = np.random.permutation(N)
TrainData1 = X1[Index1[0:N_train],:]
TestData1 = X1[Index1[N_train:N],:]
TrainLabel1 = T1[Index1[0:N_train],:]
TestLabel1 = T1[Index1[N_train:N],:]
Index2 = np.random.permutation(N)
TrainData2 = X2[Index2[0:N_train],:]
TestData2 = X2[Index2[N_train:N],:]
TrainLabel2 = T2[Index2[0:N_train],:]
TestLabel2 = T2[Index2[N_train:N],:]
Index3 = np.random.permutation(N)
TrainData3 = X3[Index3[0:N_train],:]
TestData3 = X3[Index3[N_train:N],:]
TrainLabel3 = T3[Index1[0:N_train],:]
TestLabel3 = T3[Index1[N_train:N],:]
#plt.plot(X1[:,0],X1[:,1],'or',X2[:,0],X2[:,1],'ob',X3[:,0],X3[:,1],'og')
plt.figure()
plt.plot(TrainData1[:,0],TrainData1[:,1],'or',TrainData2[:,0],TrainData2[:,1],'ob',TrainData3[:,0],TrainData3[:,1],'og')
TrainData=np.concatenate((TrainData1,TrainData2,TrainData3));
TrainLabel = np.concatenate((TrainLabel1,TrainLabel2,TrainLabel3));
N_t,d=TrainData.shape
index = np.random.permutation(N_t)
TrainData = TrainData[index,:]
TrainLabel = TrainLabel[index,:]
TestData=np.concatenate((TestData1,TestData2,TestData3));
TestLabel = np.concatenate((TestLabel1,TestLabel2,TestLabel3));
n_input_layer = 2 # 输入层
n_output_layer = 3 # 输出层
batch_size = 100
epochs=1000;
X = tf.placeholder('float',[None,2])
#Y = tf.placeholder('float',[None,n_output_layer])
Y = tf.placeholder('float')
W = tf.Variable(tf.random_normal([2,3]),'W');
b = tf.Variable(tf.random_normal([3]));
def network(data):
output = tf.add(tf.matmul(data,W),b);
return output
predict = network(X)
cost_func = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=predict,labels=Y)) + 0.01*tf.nn.l2_loss(W)
tf.summary.scalar("loss", cost_func)
#optimizer = tf.train.AdamOptimizer().minimize(cost_func)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost_func)
correct = tf.equal(tf.argmax(predict,1),tf.argmax(Y,1))
accuracy = tf.reduce_mean(tf.cast(correct,'float'))
def train_neural_network():
#saver = tf.train.Saver()
with tf.Session() as session:
session.run(tf.global_variables_initializer())
for epoch in range(epochs):
epoch_loss= 0;
_, epoch_loss = session.run([optimizer, cost_func], feed_dict={X:TrainData,Y:TrainLabel})
print(epoch, ' : ', epoch_loss)
print('准确率: ', accuracy.eval({X:TrainData, Y:TrainLabel}))
train_neural_network()