来源:https://www.cntofu.com/book/170/docs/59.md
1 将特征缩放至特定范围内
一种标准化是将特征缩放到给定的最小值和最大值之间,通常在零和一之间,或者也可以将每个特征的最大绝对值转换至单位大小。可以分别使用 MinMaxScaler 和 MaxAbsScaler 实现。
使用这种缩放的目的包括实现特征极小方差的鲁棒性以及在稀疏矩阵中保留零元素。
以下是一个将简单的数据矩阵缩放到[0, 1]的例子:
>>> X_train = np.array([[ 1., -1., 2.], ... [ 2., 0., 0.], ... [ 0., 1., -1.]]) ... >>> min_max_scaler = preprocessing.MinMaxScaler() >>> X_train_minmax = min_max_scaler.fit_transform(X_train) >>> X_train_minmax array([[0.5 , 0. , 1. ], [1. , 0.5 , 0.33333333], [0. , 1. , 0. ]])
同样的转换实例可以被用与在训练过程中不可见的测试数据:实现和训练数据一致的缩放和移位操作:
>>> X_test = np.array([[ -3., -1., 4.]]) >>> X_test_minmax = min_max_scaler.transform(X_test) >>> X_test_minmax array([[-1.5 , 0\. , 1.66666667]])
可以检查缩放器(scaler)属性,来观察在训练集中学习到的转换操作的基本性质:
>>> min_max_scaler.scale_ array([ 0.5 , 0.5 , 0.33...]) >>> min_max_scaler.min_ array([ 0\. , 0.5 , 0.33...])
如果给 MinMaxScaler 提供一个明确的 feature_range=(min, max) ,完整的公式是:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
类 MaxAbsScaler 的工作原理非常相似,但是它只通过除以每个特征的最大值将训练数据特征缩放至 [-1, 1] 范围内,这就意味着,训练数据应该是已经零中心化或者是稀疏数据。 例子::用先前例子的数据实现最大绝对值缩放操作。
以下是使用上例中数据运用这个缩放器的例子:
>>> X_train = np.array([[ 1., -1., 2.], ... [ 2., 0., 0.], ... [ 0., 1., -1.]]) ... >>> max_abs_scaler = preprocessing.MaxAbsScaler() >>> X_train_maxabs = max_abs_scaler.fit_transform(X_train) >>> X_train_maxabs array([[ 0.5, -1. , 1. ], [ 1. , 0. , 0. ], [ 0. , 1. , -0.5]]) >>> X_test = np.array([[ -3., -1., 4.]]) >>> X_test_maxabs = max_abs_scaler.transform(X_test) >>> X_test_maxabs array([[-1.5, -1. , 2. ]]) >>> max_abs_scaler.scale_ array([2., 1., 2.])
2 缩放稀疏(矩阵)数据
中心化稀疏(矩阵)数据会破坏数据的稀疏结构,因此很少有一个比较明智的实现方式。但是缩放稀疏输入是有意义的,尤其是当几个特征在不同的量级范围时。
MaxAbsScaler 以及 maxabs_scale 是专为缩放数据而设计的,并且是缩放数据的推荐方法。但是, scale 和 StandardScaler 也能够接受 scipy.sparse 作为输入,只要参数 with_mean=False 被准确传入它的构造器。否则会出现 ValueError 的错误,因为默认的中心化会破坏稀疏性,并且经常会因为分配过多的内存而使执行崩溃。 RobustScaler 不能适应稀疏输入,但你可以在稀疏输入使用 transform 方法。
注意,缩放器同时接受压缩的稀疏行和稀疏列(参见 scipy.sparse.csr_matrix 以及 scipy.sparse.csc_matrix )。任何其他稀疏输入将会 转化为压缩稀疏行表示 。为了避免不必要的内存复制,建议在上游(早期)选择CSR或CSC表示。
最后,最后,如果已经中心化的数据并不是很大,使用 toarray 方法将输入的稀疏矩阵显式转换为数组是另一种选择。
3. 缩放有离群值的数据
如果你的数据包含许多异常值,使用均值和方差缩放可能并不是一个很好的选择。这种情况下,你可以使用 robust_scale 以及 RobustScaler 作为替代品。它们对你的数据的中心和范围使用更有鲁棒性的估计。
参考:
更多关于中心化和缩放数据的重要性讨论在此FAQ中提及: Should I normalize/standardize/rescale the data?
Scaling vs Whitening 有时候独立地中心化和缩放数据是不够的,因为下游的机器学习模型能够对特征之间的线性依赖做出一些假设(这对模型的学习过程来说是不利的)。
要解决这个问题,你可以使用 sklearn.decomposition.PCA 或 sklearn.decomposition.RandomizedPCA 并指定参数 whiten=True 来更多移除特征间的线性关联。
在回归中缩放目标变量
scale 以及 StandardScaler 可以直接处理一维数组。在回归中,缩放目标/相应变量时非常有用。
4. 核矩阵的中心化
如果你有一个核矩阵 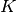 ,它计算由函数
,它计算由函数 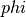 定义的特征空间的点积,那么一个
定义的特征空间的点积,那么一个 KernelCenterer 类能够转化这个核矩阵,通过移除特征空间的平均值,使它包含由函数 定义的内部产物。
5 Normalization
归一化 是 缩放单个样本以具有单位范数 的过程。如果你计划使用二次形式(如点积或任何其他核函数)来量化任何样本间的相似度,则此过程将非常有用。
这个观点基于 向量空间模型(Vector Space Model) ,经常在文本分类和内容聚类中使用.
函数 normalize 提供了一个快速简单的方法在类似数组的数据集上执行操作,使用 l1 或 l2 范式:
>>> X = [[ 1., -1., 2.], ... [ 2., 0., 0.], ... [ 0., 1., -1.]] >>> X_normalized = preprocessing.normalize(X, norm=\'l2\') >>> X_normalized array([[ 0.40..., -0.40..., 0.81...], [ 1\. ..., 0\. ..., 0\. ...], [ 0\. ..., 0.70..., -0.70...]])
preprocessing 预处理模块提供的 Normalizer 工具类使用 Transformer API 实现了相同的操作(即使在这种情况下, fit 方法是无用的:该类是无状态的,因为该操作独立对待样本).
因此这个类适用于 sklearn.pipeline.Pipeline 的早期步骤:
>>> normalizer = preprocessing.Normalizer().fit(X) # fit does nothing >>> normalizer Normalizer(copy=True, norm=\'l2\')
在这之后归一化实例可以被使用在样本向量中,像任何其他转换器一样:
>>> normalizer.transform(X) array([[ 0.40..., -0.40..., 0.81...], [ 1\. ..., 0\. ..., 0\. ...], [ 0\. ..., 0.70..., -0.70...]]) >>> normalizer.transform([[-1., 1., 0.]]) array([[-0.70..., 0.70..., 0\. ...]])
稀疏(数据)输入
函数 normalize 以及类 Normalizer 接收 来自scipy.sparse的密集类数组数据和稀疏矩阵 作为输入。
对于稀疏输入,在被提交给高效Cython例程前,数据被 转化为压缩的稀疏行形式 (参见 scipy.sparse.csr_matrix )。为了避免不必要的内存复制,推荐在上游选择CSR表示。
相关api:
class sklearn.preprocessing.MinMaxScaler(feature_range=0, 1, *, copy=True, clip=False)
Transform features by scaling each feature to a given range.
This estimator scales and translates each feature individually such that it is in the given range on the training set, e.g. between zero and one.
The transformation is given by:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
where min, max = feature_range.
This transformation is often used as an alternative to zero mean, unit variance scaling.
Read more in the User Guide.
- Parameters
- feature_rangetuple (min, max), default=(0, 1)
-
Desired range of transformed data.
- copybool, default=True
-
Set to False to perform inplace row normalization and avoid a copy (if the input is already a numpy array).
- clipbool, default=False
-
Set to True to clip transformed values of held-out data to provided
feature range.New in version 0.24.
- Attributes
- min_ndarray of shape (n_features,)
-
Per feature adjustment for minimum. Equivalent to
min - X.min(axis=0) * self.scale_ - scale_ndarray of shape (n_features,)
-
Per feature relative scaling of the data. Equivalent to
(max - min) / (X.max(axis=0) - X.min(axis=0))New in version 0.17: scale_ attribute.
- data_min_ndarray of shape (n_features,)
-
Per feature minimum seen in the data
New in version 0.17: data_min_
- data_max_ndarray of shape (n_features,)
-
Per feature maximum seen in the data
New in version 0.17: data_max_
- data_range_ndarray of shape (n_features,)
-
Per feature range
(data_max_ - data_min_)seen in the dataNew in version 0.17: data_range_
- n_samples_seen_int
-
The number of samples processed by the estimator. It will be reset on new calls to fit, but increments across
partial_fitcalls.
Methods
|
|
Compute the minimum and maximum to be used for later scaling. |
|
|
Fit to data, then transform it. |
|
|
Get parameters for this estimator. |
|
Undo the scaling of X according to feature_range. |
|
|
|
Online computation of min and max on X for later scaling. |
|
|
Set the parameters of this estimator. |
|
|
Scale features of X according to feature_range. |
>>> from sklearn.preprocessing import MinMaxScaler >>> data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] >>> scaler = MinMaxScaler() >>> print(scaler.fit(data)) MinMaxScaler() >>> print(scaler.data_max_) [ 1. 18.] >>> print(scaler.transform(data)) [[0. 0. ] [0.25 0.25] [0.5 0.5 ] [1. 1. ]] >>> print(scaler.transform([[2, 2]])) [[1.5 0. ]]
class sklearn.preprocessing.MaxAbsScaler(*, copy=True)
Scale each feature by its maximum absolute value.
This estimator scales and translates each feature individually such that the maximal absolute value of each feature in the training set will be 1.0. It does not shift/center the data, and thus does not destroy any sparsity.
This scaler can also be applied to sparse CSR or CSC matrices.
New in version 0.17.
- Parameters
- copybool, default=True
-
Set to False to perform inplace scaling and avoid a copy (if the input is already a numpy array).
- Attributes
- scale_ndarray of shape (n_features,)
-
Per feature relative scaling of the data.
New in version 0.17: scale_ attribute.
- max_abs_ndarray of shape (n_features,)
-
Per feature maximum absolute value.
- n_samples_seen_int
-
The number of samples processed by the estimator. Will be reset on new calls to fit, but increments across
partial_fitcalls.
Methods
|
|
Compute the maximum absolute value to be used for later scaling. |
|
|
Fit to data, then transform it. |
|
|
Get parameters for this estimator. |
|
Scale back the data to the original representation |
|
|
|
Online computation of max absolute value of X for later scaling. |
|
|
Set the parameters of this estimator. |
|
|
Scale the data |
Examples
>>> from sklearn.preprocessing import MaxAbsScaler >>> X = [[ 1., -1., 2.], ... [ 2., 0., 0.], ... [ 0., 1., -1.]] >>> transformer = MaxAbsScaler().fit(X) >>> transformer MaxAbsScaler() >>> transformer.transform(X) array([[ 0.5, -1. , 1. ], [ 1. , 0. , 0. ], [ 0. , 1. , -0.5]])
class sklearn.preprocessing.Normalizer(norm=\'l2\', *, copy=True)
Normalize samples individually to unit norm.
Each sample (i.e. each row of the data matrix) with at least one non zero component is rescaled independently of other samples so that its norm (l1, l2 or inf) equals one.
This transformer is able to work both with dense numpy arrays and scipy.sparse matrix (use CSR format if you want to avoid the burden of a copy / conversion).
Scaling inputs to unit norms is a common operation for text classification or clustering for instance. For instance the dot product of two l2-normalized TF-IDF vectors is the cosine similarity of the vectors and is the base similarity metric for the Vector Space Model commonly used by the Information Retrieval community.
Read more in the User Guide.
- Parameters
- norm{‘l1’, ‘l2’, ‘max’}, default=’l2’
-
The norm to use to normalize each non zero sample. If norm=’max’ is used, values will be rescaled by the maximum of the absolute values.
- copybool, default=True
-
set to False to perform inplace row normalization and avoid a copy (if the input is already a numpy array or a scipy.sparse CSR matrix).
Methods
|
|
Do nothing and return the estimator unchanged |
|
|
Fit to data, then transform it. |
|
|
Get parameters for this estimator. |
|
|
Set the parameters of this estimator. |
|
|
Scale each non zero row of X to unit norm |
Examples
>>> from sklearn.preprocessing import Normalizer >>> X = [[4, 1, 2, 2], ... [1, 3, 9, 3], ... [5, 7, 5, 1]] >>> transformer = Normalizer().fit(X) # fit does nothing. >>> transformer Normalizer() >>> transformer.transform(X) array([[0.8, 0.2, 0.4, 0.4], [0.1, 0.3, 0.9, 0.3], [0.5, 0.7, 0.5, 0.1]])