IO模型
IO是Input/Output的缩写。Linix网络编程中有五种IO模型:
- blocking IO(阻塞IO)
- nonblocking IO(非阻塞IO)
- IO multiplexing(多路复用IO)
- signal driven IO(信号驱动IO)
- asynchronous IO(异步IO)
简介
- Java.io包基于流模型实现,提供File抽象、输入输出流等IO的功能。交互方式是同步、阻塞的方式,在读取输入流或者写入输出流时,在读、写动作完成之前,线程会一直阻塞。java.io包的好处是代码比较简单、直观,缺点则是IO效率和扩展性存在局限性,容易成为应用性能的瓶颈。
- Java.net下面提供的部分网络API,比如Socket、ServerSocket、HttpURLConnection 也时常被归类到同步阻塞IO类库,网络通信同样是IO行为
- Java 1.4中引入了NIO框架(java.nio 包),提供了Channel、Selector、Buffer等新的抽象,可以构建多路复用IO程序,同时提供更接近操作系统底层的高性能数据操作方式。
- Java7中,NIO有了进一步的改进,也就是NIO2,引入了异步非阻塞IO方式,也被称为AIO(Asynchronous IO),异步IO操作基于事件和回调机制。
首先了解下同步\异步、阻塞\非阻塞的区别
同步与异步
同步和异步是针对的是用户进程与内核的交互方式。
- 同步指的是用户进程触发IO操作并等待或者轮询的去查看IO操作是否就绪。例如:自己去银行办理业务,自己只能一直干这件事,其他事情只能等这件是做完后再做
- 异步指的是用户进程触发IO操作以后便开始做其他的事情,而当IO操作已经完成的时候会得到IO完成的通知。例如:委托亲属去银行办理业务,然后自己可以去干别的事。(使用异步I/O时,Java将I/O读写委托给OS处理,需要将数据缓冲区地址和大小传给OS)。
阻塞与非阻塞
阻塞和非阻塞是针对进程在访问数据的时候,根据IO操作的就绪状态来采取的不同方式。
- 阻塞指的是当试图对该文件描述符进行读写时,如果当时没有东西可读,或暂时不可写,程序就进入等待状态,直到有东西可读或可写为止。去办理业务时,人过多需要排队,此时就在原地等待,一直等到自己为止。
- 非阻塞指的是如果没有东西可读,或不可写,读写函数马上返回,而不会等待。在银行里办业务时,领取一张小票,之后我们可以玩手机,或与别人聊聊天,当轮到我们时,银行的喇叭会通知,这时候我们就可以去办业务了。
注意,这里办业务的时候,还是需要我们也参与其中的,这和异步是完全不同的,因此同步\异步、阻塞\非阻塞,是完全不同的两个概念,二者不要混淆
I/O模型分类
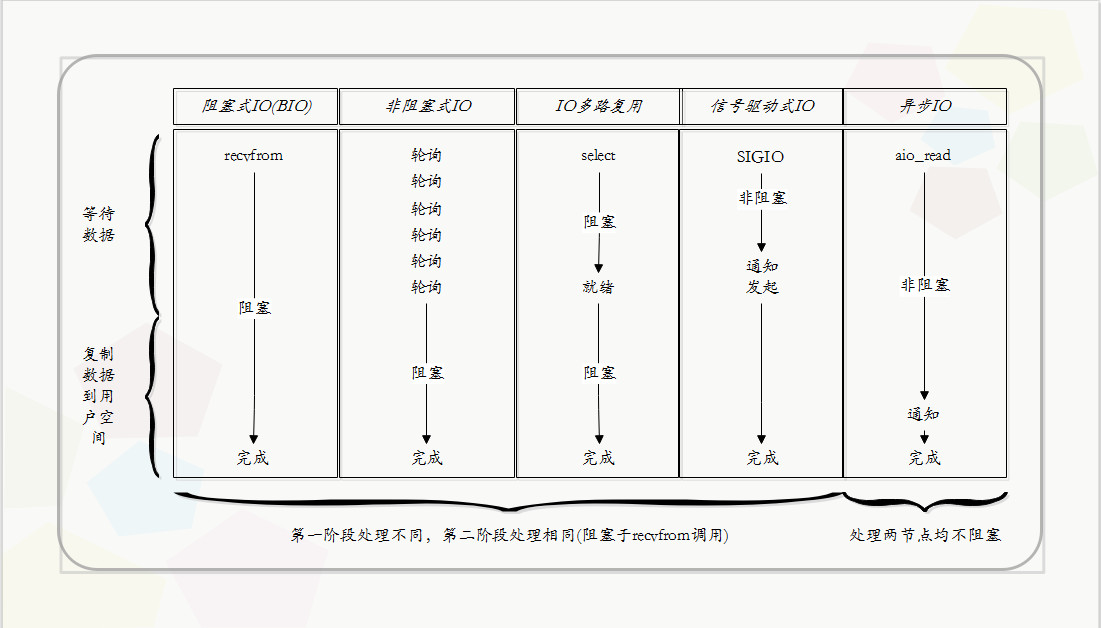
应用程序向操作系统发出IO请求:应用程序发出IO请求给操作系统内核,操作系统内核需要等待数据就绪,这里的数据可能来自别的应用程序或者网络。一般来说,一个IO分为两个阶段:
- 等待数据:数据可能来自其他应用程序或者网络,如果没有数据,应用程序就阻塞等待。
- 拷贝数据:将就绪的数据拷贝到应用程序工作区。
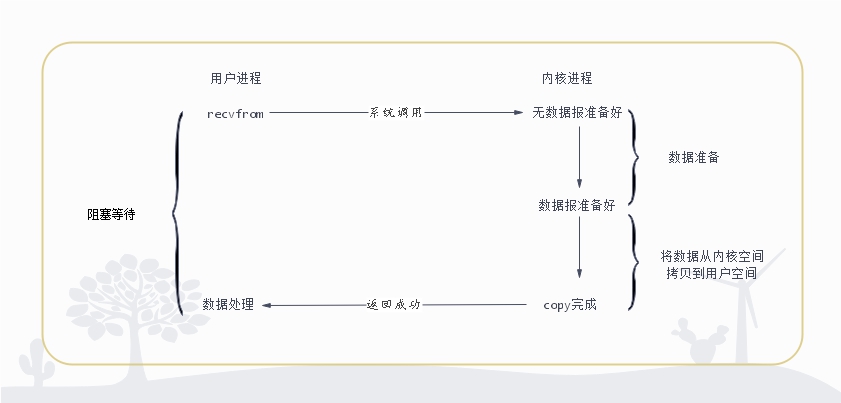
在Linux系统中,操作系统的IO操作是一个系统调用recvfrom(),即一个系统调用recvfrom包含两步,等待数据就绪和拷贝数据。
同步阻塞IO
在此种方式下,用户进程在发起一个IO操作以后,必须等待IO操作的完成,只有当IO操作完成之后,用户进程才能运行。JAVA传统的BIO属于此种方式。(jdk1.4以前)
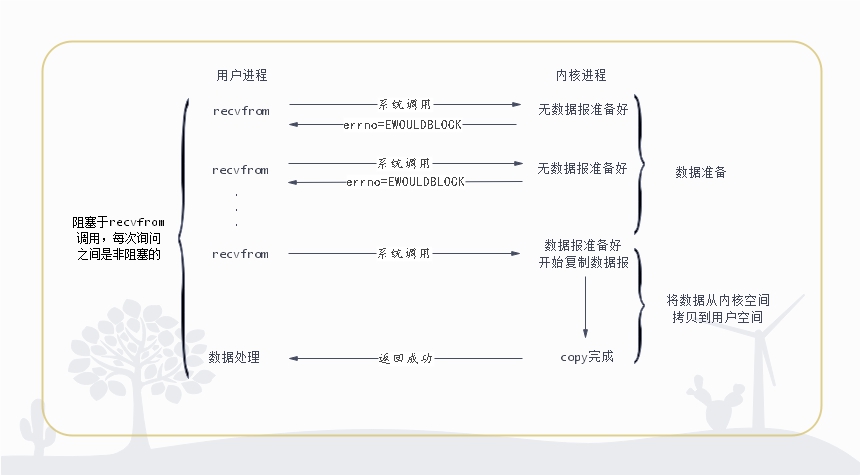
同步非阻塞IO
JAVA NIO(jdk1.4以后引入)
在此种方式下,用户进程发起一个IO操作以后边可返回做其它事情,但是用户进程需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问,从而引入不必要的CPU资源浪费。JAVA的NIO就属于同步非阻塞IO
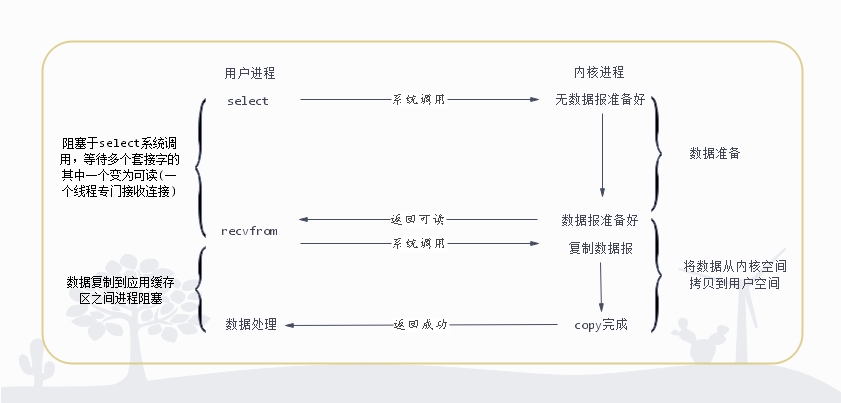
多路复用IO
redis、nginx、netty;reactor模式
select,epoll;有时也称这种IO方式为事件驱动IO。
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程.
多路复用中,通过select函数,可以同时监听多个IO请求的内核操作,只要有任意一个IO的内核操作就绪,都可以通知select函数返回,再进行系统调用recvfrom()完成IO操作。
这个过程应用程序就可以同时监听多个IO请求,这比起基于多线程阻塞式IO要先进得多,因为服务器只需要少数线程就可以进行大量的客户端通信。
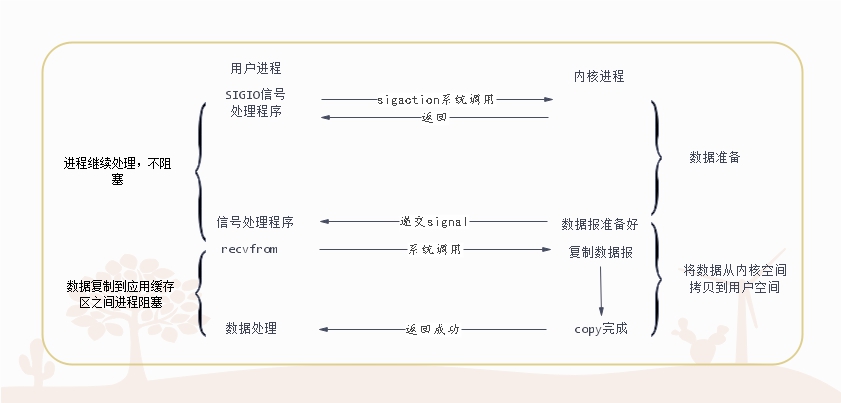
信号驱动式IO模型
在unix系统中,应用程序发起IO请求时,可以给IO请求注册一个信号函数,请求立即返回,操作系统底层则处于等待状态(等待数据就绪),直到数据就绪,然后通过信号通知主调程序,主调程序才去调用系统函数recvfrom()完成IO操作。
信号驱动也是一种非阻塞式的IO模型,比起上面的非阻塞式IO模型,信号驱动式IO模型不需要轮询检查底层IO数据是否就绪,而是被动接收信号,然后再调用recvfrom执行IO操作。
比起多路复用IO模型来说,信号驱动IO模型针对的是一个IO的完成过程, 而多路复用IO模型针对的是多个IO同时进行时候的场景。
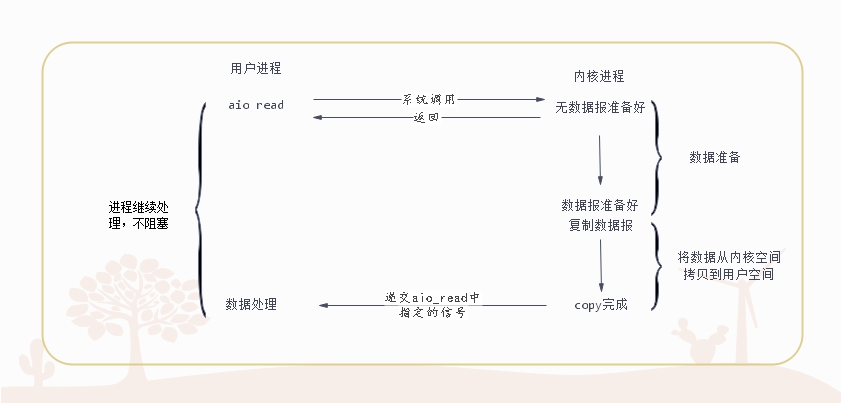
异步IO
在此种模式下,整个IO操作(包括等待数据就绪,复制数据到应用程序工作空间)全都交给操作系统完成。数据就绪后操作系统将数据拷贝进应用程序运行空间之后,操作系统再通知应用程序,这个过程中应用程序不需要阻塞
区别
如果你在烧水:
- 同步阻塞:你将水放在炉子上,然后在那儿等着,还要一直观察:水烧开了没啊!
- 同步非阻塞:你将水放在炉子上,就去看电视了了。每过一会,就到炉子边观察:水烧开了没啊!
- 多路复用:有人改进了烧水壶,水开了之后会自动发出哨声,你只需要安心看电视等待哨响通知你水烧开了。
- 异步非阻塞:你安排其他人烧水,水烧开后放在特地场合,会打电话通知你,安心看电视等待就可以了。
阻塞、非阻塞、多路IO复用,都是同步IO,异步必定是非阻塞的,所以不存在异步阻塞和异步非阻塞的说法。真正的异步IO需要CPU的深度参与。换句话说,只有用户线程在操作IO的时候根本不去考虑IO的执行,全部都交给CPU去完成,而只需要等待一个完成信号的时候,才是真正的异步IO。所以,fork子线程去轮询、死循环或者使用select、poll、epoll,都不是异步
比较经典的一个举例
-
阻塞I/O模型
老李去火车站买票,排队三天买到一张退票。 耗费:在车站吃喝拉撒睡 3天,其他事一件没干。
-
非阻塞I/O模型
老李去火车站买票,隔12小时去火车站问有没有退票,三天后买到一张票。耗费:往返车站6次,路上6小时,其他时间做了好多事。
-
I/O复用模型
1.select/poll 老李、老王、老刘…一行人去火车站买票,一起委托给黄牛(select黄牛最大只能接1024个人的订单/pool黄牛不限制),select/pool黄牛一直等待出票结果,待黄牛取到票后,不知道这张票是属于谁的(需要根据票面逐一询问),确认后通知相应人去火车站交钱领票。
2.epoll 老李、老王、老刘…一行人(无人员个数限制)去火车站买票,一起委托给黄牛,黄牛买到后不需要确认就可以知道这张票的委托人是谁,然后通知其去火车站交钱领票。
多路复用的意思是:黄牛在承接老李的订单之后,同时也接了老王、老刘的购票订单;大家使用同一个黄牛
-
信号驱动I/O模型
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李,然后老李去火车站交钱领票。 耗费:往返车站2次,路上2小时,免黄牛费100元,无需打电话,也不需要黄牛
-
异步I/O模型
老李去火车站买票,给售票员留下电话,有票后,售票员快递送票上门后电话通知其收货。 耗费:往返车站1次,路上1小时,免黄牛费100元,无需打电话,也不需要黄牛
再谈IO多路复用
I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
多路复用如下面所示:指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态来同时管理多个I/O流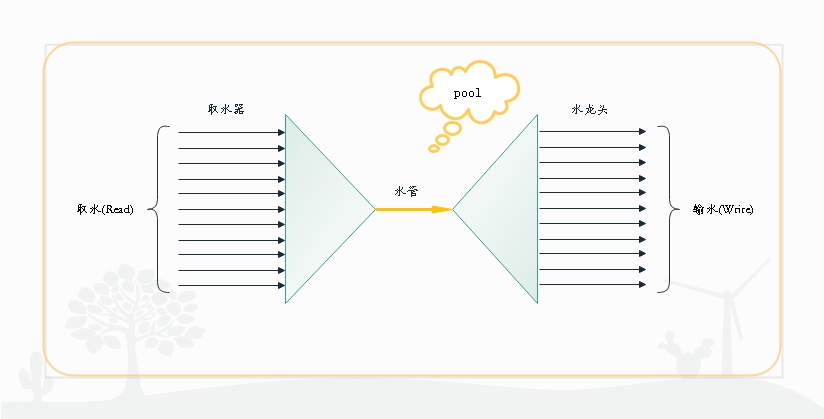
个人的一些理解:
如上图做一个简单的比喻:左边有若干取水器,需要到右边水龙头进行取水操作,每个取水器和水龙头是一一对应的关系,但是中间段是断开的,需要将水管连接上(一个水管相当于一个IO线程),才可以进行取水操作了(注意水龙头不是一直都有水流的,只有当取水器连接上才会触发输水操作)。下面依次对不同的IO模型进行讲解:
1、传统阻塞BIO:每个取水器和水龙头之间都需要一个连接水管,水管连接上触发取水操作,水龙头才会输水。这样有几个取水器就需要几个水管,另外水管接上之后并不会马上就能取到水,之间一直处于阻塞状态,当取水器过多时没有足够的水管来进行连接
线程池模式:水池中存在10根水管,每当取水器有取水请求时,就去水池中拿一根水管使用,水管会根据取水器编号接到相应的水龙头上。当取水器请求过多时,需要不停的进行水管切换。
2、多路复用IO:
select/poll:全部的取水器均复用一根水管,没有多余的水管可用,所有的取水器均接到这一根水管上。(区别是select模式仅支持1024个取水器的接入,而poll不限制取水器个数)。当水龙头有水流过来时,水管会提前收到通知,但不知道是哪个水龙头。则此时水管需要每个水龙头都接上试一下,当发现其中一个水龙头有水流时则将其运到与其相连的取水器中。
epoll部的取水器均复用一根水管,没有多余的水管可用,所有的取水器均接到这一根水管上。(与select/poll区别是:当水龙头有水流过来时,水管就已经知道是哪根水龙头在运水了,直接将水管接上相应的水龙头即可)。
伪代码描述各IO区别
-
非阻塞忙轮询式
while true { for i in fd[] { if i has data read until unavailable } }把所有流从头到尾查询一遍,就可以处理多个流了,但这样做很不好,因为如果所有的流都没有I/O事件,白白浪费CPU时间片
-
select:服务端一直在轮询、监听如果有客户端链接上来就创建一个连接放到数组A中,继续轮询这个数组,如果在轮询的过程中有客户端发生IO事件就去处理;select只能监视1024个连接(一个进程只能创建1024个文件);而且存在线程安全问题;
while true { select(fds[]) //阻塞这里,直到有一个流有I/O事件时,才往下执行,数组的大小只有1024 for i in fds[] { if i has data read until unavailable } }它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长
-
poll:在select做了许多修复,比如不限制监测的连接数;但是也有线程安全问题;
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
-
epoll:也是监测IO事件,但是如果发生IO事件,它会告诉你是哪个连接发生了事件,就不用再轮询访问。而且它是线程安全的,但是只有linux平台支持;
while true { active_fds[] = epoll_wait(epollfd) for i in active_fds[] { read or write till } }epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))