我们知道在 RR 级别下,对于是一个事务来说,读到的值应该是相同的,但有没有想过为什么会这样,它是如何实现的?会不会有一些特殊的情况存在?本篇文章会详细的讲解 RR 级别下事务被隔离的原理。在阅读后应该了解如下的内容:
- 了解 MySQL 中的两种视图
- 了解 RR 级别下,如何实现的事务隔离
- 了解什么是当前读,以及当前读会造成那些问题
明确视图的概念
在 MySQL 中,视图有两种。第一种是 View,也就是常用来查询的虚拟表,在调用时执行查询语句从而获取结果, 语法如 create view.
第二种则是存储引擎层 InnoDB 用来实现 MVCC(Mutil-Version Concurrency Control | 多版本并发控制)时用到的一致性视图 consistent read view, 用于支持 RC 和 RR 隔离级别的实现。简单来说,就是定义在事务执行期间,事务内能看到什么样的数据。
事务真正的启动时机:
在使用 begin 或 start transation 时,事务并没有真正开始运行,而是在执行一个对 InnoDB 表的操作时(即第一个快照读操作时),事务才真正启动。
如果想要立即开始一个事务,可以用 start transaction with consistent snapshot 命令。
不期待的结果,事务没有被隔离
在之前 MySQL 事务 介绍中,知道在 RR 的级别的事务下,如果其他事务修改了数据,事务中看到的数据和启动事务时的数据是一致的,并不会受其他事务的影响。可是,有没有什么特殊的情况呢?
看下面这个例子:
创建表:
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, k) values(1,1),(2,2);按照下图开启事务:

这时对于事务 A 来说,查询 k 的值为 1, 而事务 B 的 K 为 3. 不是说,在 RR 级别下的事务,不受其他事务影响吗,为了事务 B 的结果为 3 而不是所期待的 2. 这就涉及到了 MVCC 中 “快照” 的工作原理。
MVCC 的实现 - 快照
什么是 “快照”?
在 RR 级别下,事务启动时会基于整库拍个“快照”,用于记录当前状态下的数据信息。可这样的话,对于库比较大的情况,事务的启动应该非常慢。可实际上的执行过程非常快,原因就在于 InnoDB 中的实现。
“快照”的实现
在 InnoDB 中,每个事务都有唯一的事务 ID,叫做 transaction id. 在事务开始时,按照严格递增的顺序向 InnoDB 事务系统申请。
数据库中,每行数据具有多个版本。在每次开启更新的事务时,都会生成一个新的数据版本,并把 transaction id赋值给当前数据版本的事务 ID,记为 row trx_id.
如下图所示,对于同一行数据连续更新了 4 次,对应 4 个版本如下。对于最新版本 V4 情况,K 为 22,是被事务 id 为 25 所更新的,进而 row trx_id 是 25.

在每次更新时,都会生成一条回滚日志(undo log),上图中三个虚拟箭头(U1,U2,U3)就是 undo log. 每次开启事务的视图 V1,V2,V3 物理上并不真实存在,而是通过当前事务版本和 undo log 计算出来。
了解了 row trx_id 和 transaction id,就可以进一步了解事务具体是如何进行隔离的了。
事务隔离的实现
在 RR 级别下,要想实现一个事务启动时,能够看到所有已经提交的事务结果。在事务执行期间,其他事务的更新均不可见。
只需要在事情启动时规定,以启动的时刻为准,如果一个数据版本在启动前生成,就可以查看。如果在启动后生成,则不能查看,通过 undo log 一直查询上一个版本数据,直到找到启动前生成的数据版本或者自己更新的数据才结束。
在具体实现上,InnoDB 为每个事务构造一个数组,用来保存事务启动瞬间,当前正在活跃(启动没有提交)的所有事务 ID. 数组里 ID 最小为低水位,当前系统里面创建过的事务 ID 最大值 + 1 为高水位。这个数组和高水位,就组成了当前事务的一致性视图(read-view),如下图所示。

数据是否看见,就是通过比较数据的 row trx_id 和 一致性视图的对比而得到的。
在比较时:
一、如果 row trx_id 出现在绿色部分,表示该版本是已提交的事务或者当前的事务自己生成的,该数据可见。
| 事务A | 事务B |
|---|---|
| start transaction with consistent snapshot; | |
| update t set k = k+1 where id=1; | |
| commit; | |
| start transaction with consistent snapshot; | |
| select * from t where id=1; |
事务 A 修改 k 值后提交,接着事务 B 查询 k 值。这时对于启动的事务 B 来说,k 值的 row trx_id 等于事务 A 的transaction id. 而事务 B 在 事务 A 之后申请,假设当前活跃事务只有 B。B 的 transaction id 肯定大于事务 A,所以当前版本 row trx_id 一定小于低水位,进而 k 值为 A 修改后的值。
二、如果在红色部分,表示由未来的事务生成的,该数据不可见。
| 事务A | 事务B |
|---|---|
| start transaction with consistent snapshot; | |
| start transaction with consistent snapshot; | |
| update t set k = k+1 where id=1; | |
| commit; | |
| select * from t where id=1; |
事务 A 开启后,查询 k 值,但未提交事务。事务 B 在事务 A 开启后修改 K 值。此时对于事务 A 来说, 修改后 k 值的 row trx_id 等于事务B transaction id. 假设当前的活跃的只有事务 A,则 row trx_id 大于高水位的值,所以事务 B 的修改对 A 不可见。
三、如果落在黄色部分,两种情况
a. row trx_id 在数组中,表示该版本是由未提交的事务生成的,不可见。
| 事务A | 事务B |
|---|---|
| start transaction with consistent snapshot; | |
| start transaction with consistent snapshot; | |
| update t set k = k+1 where id=1; | |
| select * from t where id=1; |
事务 A,B 先后开启,假设只有 A,B 两个活跃的事务。此时对于事务 B 来说一致性视图中的数组包含事务A和B 的 transaction id.
当事务 B 查询 k 值时,发现数组中包含事务 A 的 transaction id,说明是未提交的事务。所以不可见。
b. row trx_id 不在数组中,表示该版本是由已提交的事务生成,可见。
| 事务A (transaction id = 100) | 事务B (transaction id = 101) | 事务 C (transaction id = 102) |
|---|---|---|
| start transaction with consistent snapshot; | ||
| update t set k = k+1 where id=1; | start transaction with consistent snapshot; | |
| update t set k = k+1 where id=1; | ||
| commit; | ||
| start transaction with consistent snapshot; | ||
| select * from t where id=1; | ||
假设当前只活跃 A,C 两个事务。对于事务 C 来说,一致性视图数组为[100,102]. 当前 k 的 row trx_id 为 101,不在一致性数组中。说明是已经提交事务,所以数据可见。
InnoDB 就是利用了所有数据都有多个版本这个特性,实现了秒级创建快照的能力。
现在回到文章开始的三个事务,现在分析下为什么事务 A 的结果是 1。
假设如下:
- 在 A 启动时,系统只有一个活跃的事务 ID 为 99.
- A,B,C 事务的版本号为 100,101,102 且当前系统中只有这四个事务。
- 三个事务开始前,(1,1)对应 row trx_id 为 90.
这样对于事务 A,B,C 中一致性数组和 row trx_id 如下:

右侧显示的回滚段的内容,第一次更新为事务 C,其 row trx_id 等于 102. 值为(1,2)。最新 row trx_id 为事务 B 的 101,值为(1,3)。
对于事务 A 来说,视图数组为 [99,100]。读取流程如下:
- 获取当前 row trx_id 为 101 的数据。发现比高水位大,落在红色,不可见。
- 向上查找,发现 row trx_id 为 102 的,比高水位大,不可见。
- 向上查找,发现 row trx_id 为 90,比低水位小,落在绿色可见。
这时事务 A 无论在什么时候查询,看到的结果都一致,这被称为一致性读。
上面的判断逻辑为代码逻辑,现在翻译成便于理解的语言,对于一个事务视图来说,除了自己的更新可见外:
- 版本未提交,不可见(包含了还未提交的事务,或者开始同时活跃,但先一步提交的事务);
- 版本已提交,在视图后创建提交的,不可见。
- 版本已提交,在视图创建前提交,可见。
现在应该清楚,可重复读的能力就是通过一致性读实现的。可是在文章开始部分事务 B 的更新语句如果按照一致性读的情况,事务 C 在事务 B 之后提交,结果应该是(1,2)不是 (1,3)。原因就在于当前读的影响。
当前读的影响
对于文章开头部分的事务 B 来说,如果在更新操作前查询一次数据,返回结果确实是 1。但由于更新操作,并不是在历史版本上更新,否则事务 C 的更新就会被覆盖。因此事务 B 的更新操作是在(1,2)的基础上操作的。
什么是当前读?
在更新操作时,都是先读后写,这个读,就是只能读当前的值(最新已经提交的值),进而称为“当前读”。
除 update 语句外,给 select 语句加锁,也是当前读。锁的类型可以是读锁(S锁,共享锁)和写锁(X锁,排他锁)。
比如想让事务 A 的查询语句获取当前读中的值:
# 共享锁
mysql> select k from t where id=1 lock in share mode;
# 排它锁
mysql> select k from t where id=1 for update;在当前读下,快照查询的过程
在事务 B 更新时,当前读拿到的值为(1,2),更新后生成的新版本数据为(1,3),当前版本的 row trx_id 101.
所以在接下里的执行的查询语句时,当前 row trx_id 为101,判断为自己更新的,所以可见。所以查询结果是(1,3)。
假设事务 C 改成如下事务 C' 这样,在事务 B 更新后,再提交。

这时虽然(1,2)已经生成了,但根据两阶段锁协议,由于事务 C’ 没有提交,没有释放写锁。这时事务 B 就会被锁住,等到其他事务释放后,再继续当前读。
可重复读的核心就是一致性读,而事务更新数据的时候,只能用当前读。如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
读提交下的事务隔离实现
读提交和可重复读的逻辑类似,主要区别为:
- 在 RR 下,事务开始时就创建一致性视图,之后事务中的查询都共用这个一致性视图。
- 在 RC 下,每个语句执行前会重新算出一个视图。
重新看下文章开头部分读提交状态下的事务状态图:

对于事务 A 来说,查询语句的时刻会重新计算视图,此时(1,3),(1,2)都是在该语句前生成的。
此时对于该语句来说:
- (1,3)属于版本未提交,不可见。
- (1,2)属于版本已提交,在视图前创建提交,版本可见。
所以结果为 k=2.
应用场景
级别为 RR。
场景1-文章开头例子,造成查询结果不一致的情况
场景2- 假设场景:事务中无法更新的情况
表结构为:
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, c) values(1,1),(2,2),(3,3),(4,4);这里想把 c 和 id 相等的行的 c 值清零,却出现无法修改的现象。
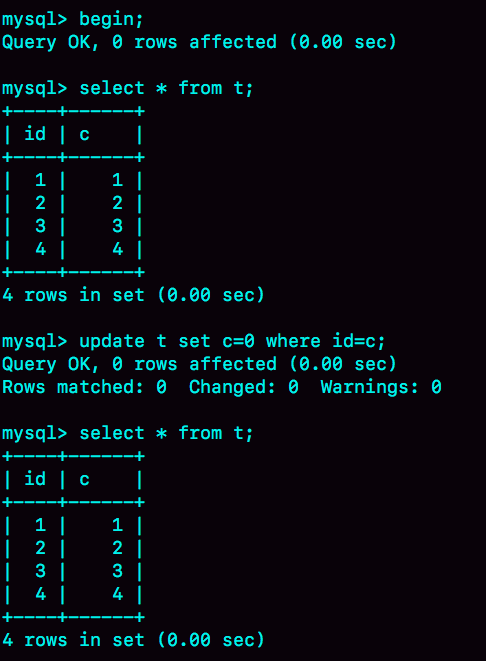
这里在上面开启的事务更新前,开启一个新事务修改所有行中的 c 值就可以。
方式1:
| 事务A | 事务B |
|---|---|
| start transaction with consistent snapshot; | |
| update t set c = c+1; | |
| update set c=0 where id =c; | |
| select * from t; |
事务 A 的更新语句是当前读,会先将最新的数据版本读取出,然后更新,但由于数据是最新版本,没有满足更新的 where 语句的行(因为 c 值被加 1),这时更新失败。所以原数据行的 row trx_id 没有变,还是等于事务 B 的 ID。之后执行 select,由于数据行是事务 B 的 trx_id, 也就是属于版本已提交,在视图后创建提交,属于不可见的情况,所以查出来的数据还是事务 B 更新前的数据。
方式2:
| 事务A | 事务B |
|---|---|
| start transaction with consistent snapshot; | |
| select * from t; | |
| start transaction with consistent snapshot; | |
| select * from t; | |
| update t set c = c+1; | |
| commit; | |
| update set c=0 where id =c; | |
| select * from t; |
在事务 A 启动时,事务 B 属于活跃的事务,虽然之后提交了,但也属于是版本未提交,不可见的情况。
场景3 - 实际场景:实现乐观锁后,无法更新的情况。
下面使用乐观锁出现的情况就是上面场景 1 出现的实际场景。
在实现乐观锁后,通常会基于 version 字段进行 cas 式的更新(update ...set ... where id = xxx and version = xxx),当 version 被其他事务抢先更新时,自己所在事务更新失败,这时由于所在 row 的 trx_id 没有改变成自己更新事务的 id(由于更新失败),再次 select 还是过去的旧值,造成明明值没有变,却没法更新的情景。
解决方式就是在失败后,重新开启一个事务。判断成功的标准一般是判断 affected_rows 是不是等于预期值。
CAS:Compare and Swap,即比较再交换。CAS是一种无锁算法,CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
总结
在 MySQL 中视图分为两种,一种是虚拟表另一种则是一致性视图。
在 RR 级别下开启事务后,会拍下快照,快照里,每个事务会有自己的唯一 ID,数据库中的每行数据存在多个版本,在执行更新语句时,为会每行数据添加一个新的版本,其中 row trx_id 就是所在更新事务的 ID.
事务隔离的实现,就是规定以事务开启的时刻为准,之前提交的事务数据可见,之后提交的事务数据不可见。在具体实现上,通过开启一个数组,该数组记录了当前时刻所有活跃的事务 ID. 而开头提到的一致性视图就是由该数组组成。通过比较该数组和数据库中数据多个版本的 row trx_id 来达到可见和不可见的效果。
当前读会读取已经提交完成的数据,这就会导致一致性视图的查询结果不一致,或者无法更新的奇怪现象。
RC 和 RR 的区别为,RC 承认的是语句前已经提交完成的数据。而 RR 承认在事务启动前已经提交完成的数据。