Redis被广泛使用的一个很重要的原因是它的高性能。因此我们必要要重视所有可能影响Redis性能的因素、机制以及应对方案。影响Redis性能的五大方面的潜在因素,分别是:
这一讲,我们来学习一下CPU对Redis的性能影响及应对方法。
主流CPU架构
学习之前,我们先来了解主流CPU架构有哪些,有什么特点,以便我们更好地了解CPU是如何影响Redis的。
CPU多核架构
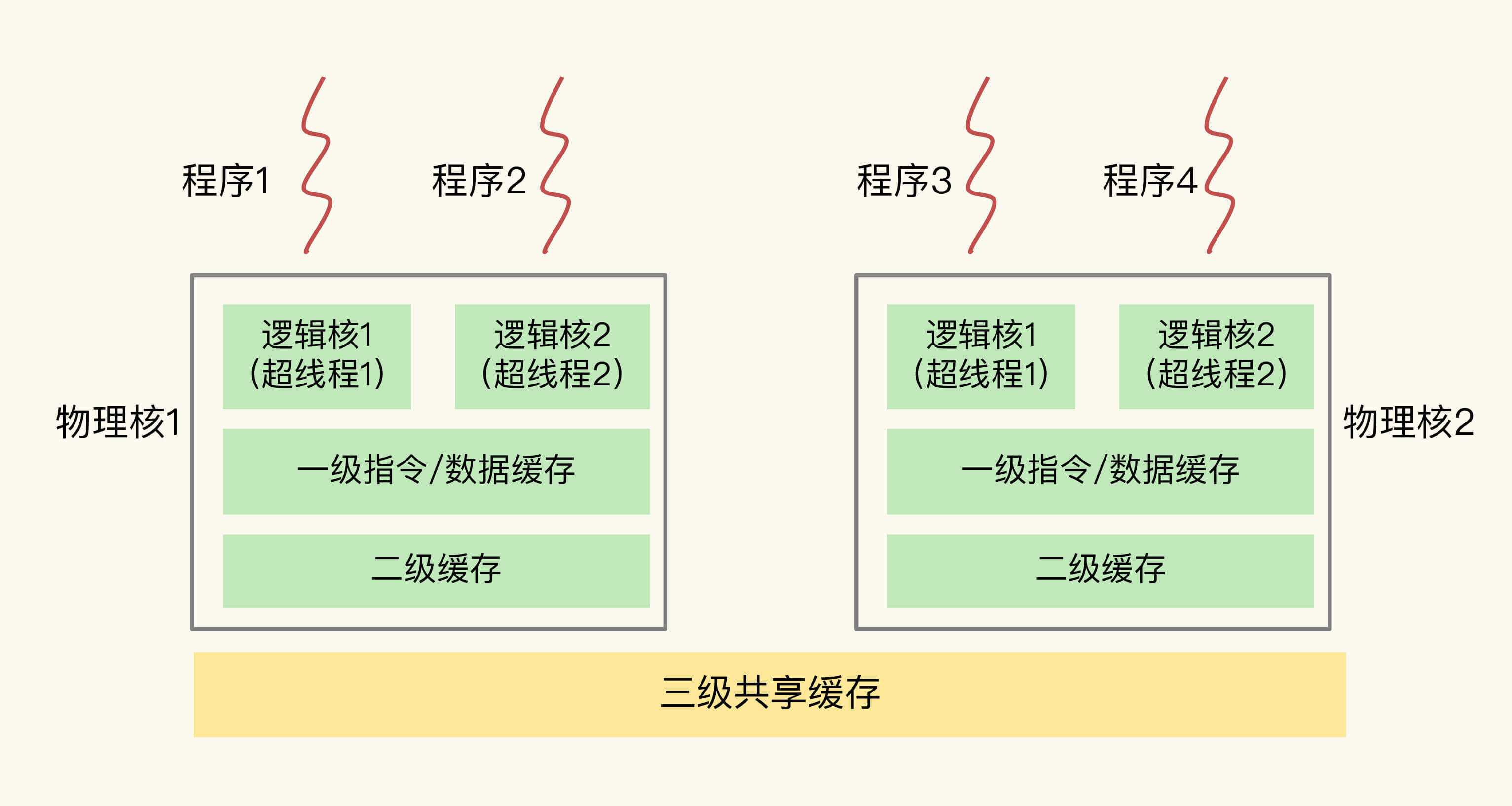
- 一个CPU处理器中一般有多个运行核心,称为物理核。
- 物理核包括私有的一级指令/数据缓存(L1缓存)和二级缓存(L2缓存)。
- 每个物理核会运行两个超线程,也叫作逻辑核。同一个物理核的逻辑核会共享使用L1、L2缓存。
- 不同的物理核共享三级缓存(L3缓存)
多CPU Socket架构
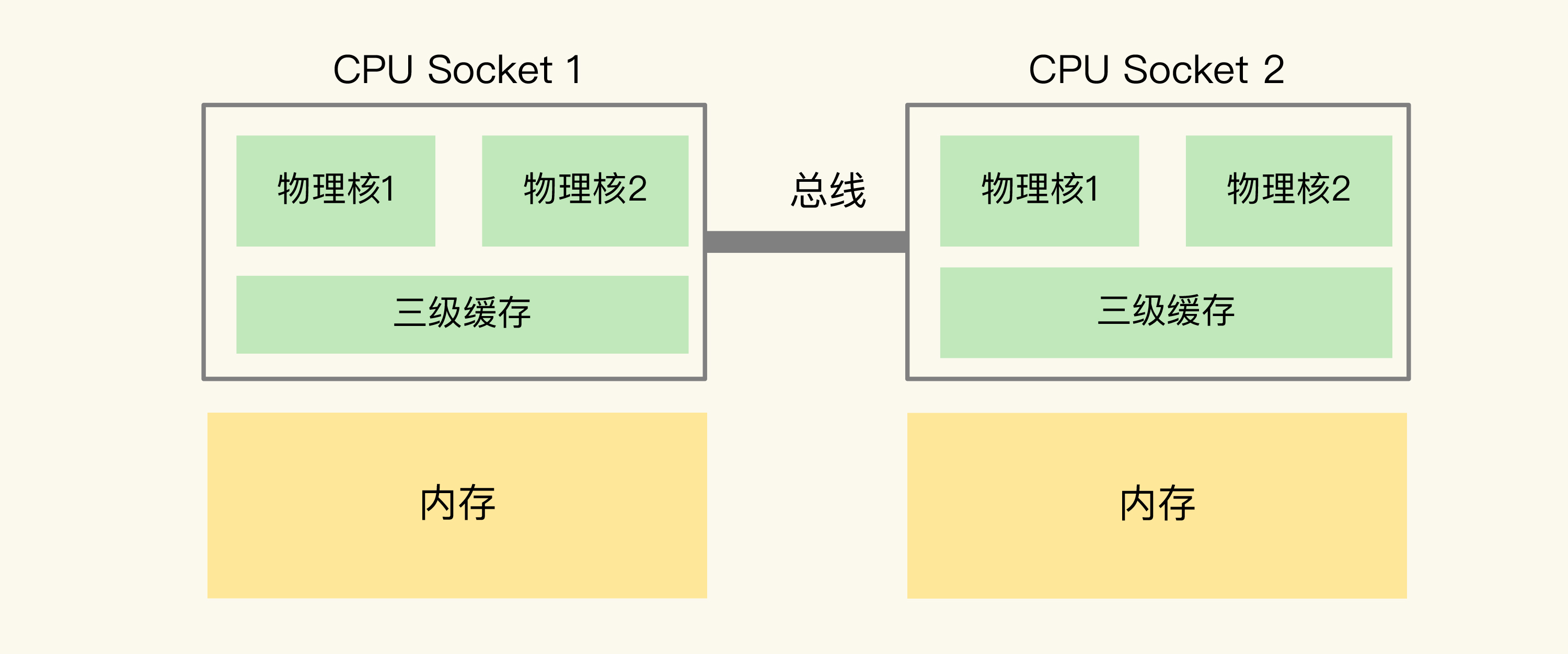
在多CPU架构上,应用程序可以在不同的处理器上运行。
应用程序在不同的Socket间调度运行时,访问之前的Socket的内存,这种访问属于远端内存访问。
和访问Socket直接连接的内存相比,远端内存访问会增加应用程序的延迟。
把这个架构称为非统一内存访问架构(Non-Uniform Memory Access,NUMA架构)。
CPU多核对Redis性能的影响
如果在CPU多核场景下,Redis实例被频繁调度到不同CPU核上运行的话,那么,对Redis实例的请求处理时间影响就更大了。每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求。
要避免Redis总是在不同CPU核上来回调度执行。最直接的方法是把Redis实例和CPU核绑定了,让一个Redis实例固定运行在一个CPU核上。
通过taskset命令进行绑核:
taskset -c 0 ./redis-server
绑核不仅对降低尾延迟有好处,同样也能降低平均延迟、提升吞吐率,进而提升Redis性能。
CPU的NUMA架构对Redis性能的影响
在实际应用Redis时,有一种做法:为了提升Redis的网络性能,把操作系统的网络中断处理程序和CPU核绑定。
在CPU的NUMA架构下,当网络中断处理程序、Redis实例分别和CPU核绑定后,就会有一个潜在的风险:如果网络中断处理程序和Redis实例各自所绑的CPU核不在同一个CPU Socket上,那么,Redis实例读取网络数据时,就需要跨CPU Socket访问内存,这个过程会花费较多时间。
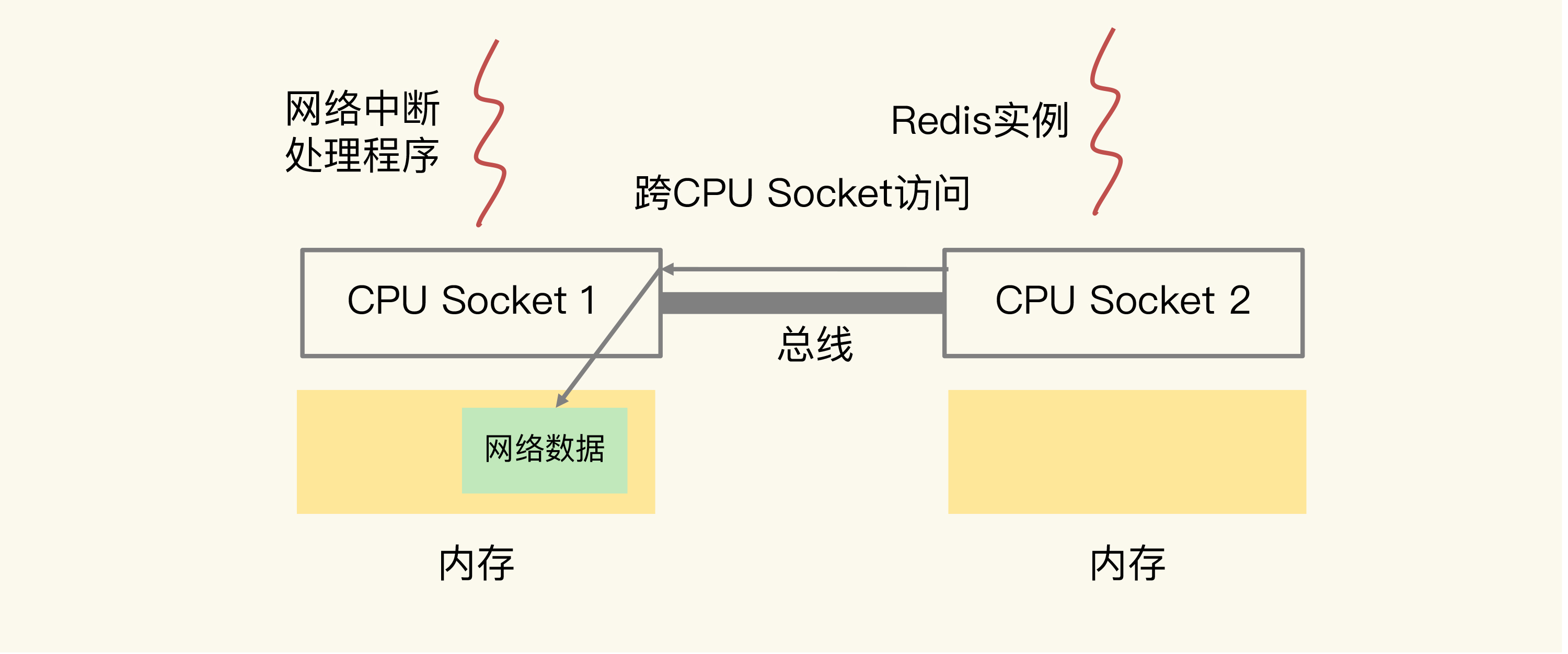
为了避免Redis跨CPU Socket访问网络数据,我们最好把网络中断程序和Redis实例绑在同一个CPU Socket上,这样一来,Redis实例就可以直接从本地内存读取网络数据了。
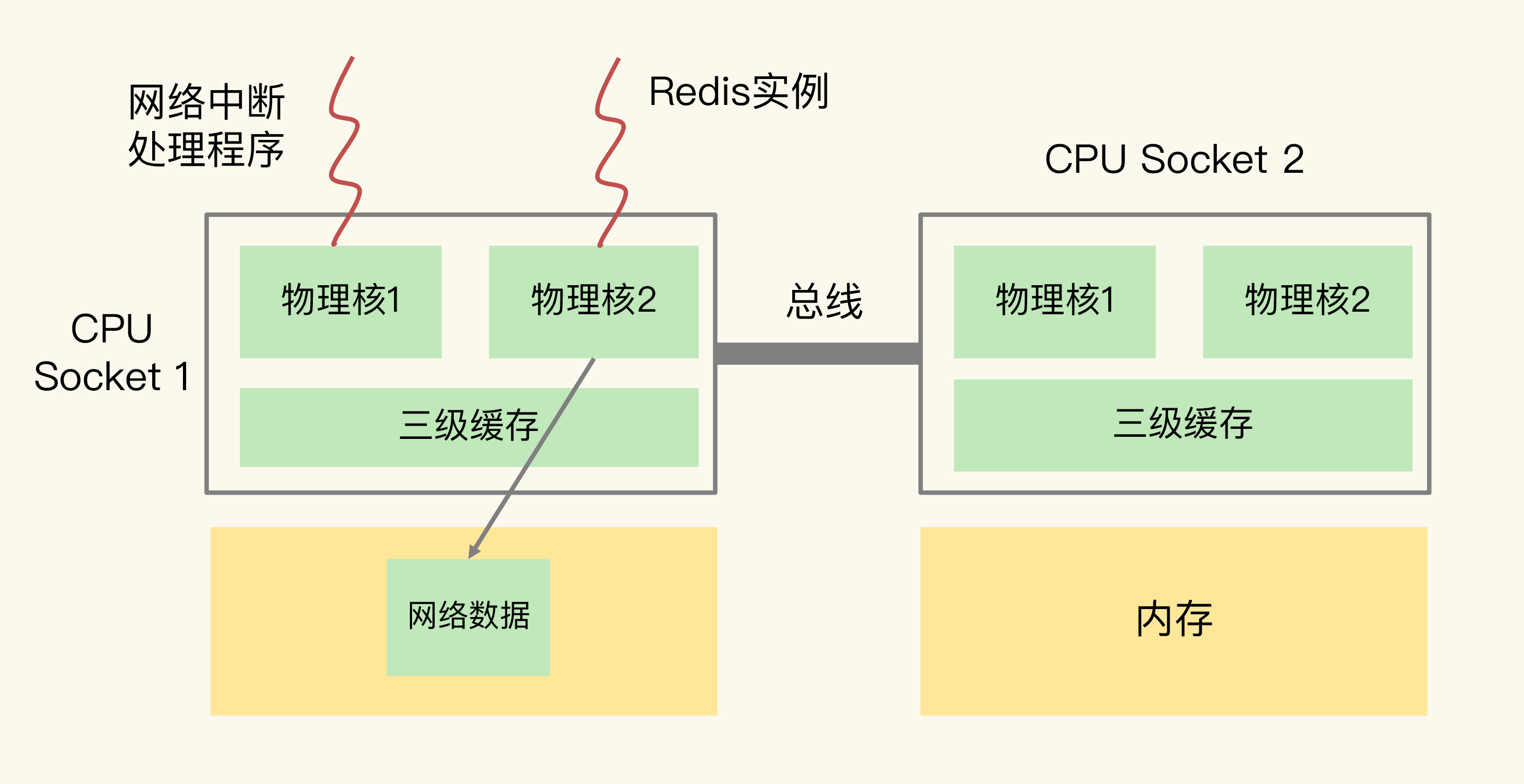
CPU的NUMA架构下进行绑定要注意CPU核的编号规则,可以执行lscpu命令来查看核的编号。
lscpu Architecture: x86_64 ... NUMA node0 CPU(s): 0-5,12-17 NUMA node1 CPU(s): 6-11,18-23 ...
不过,凡事都有两面性,绑核也存在一定的风险。接下来就来了解下它的潜在风险点和解决方案。
绑核的风险和解决方案
方案一:一个Redis实例对应绑一个物理核
在给Redis实例绑核时,我们不要把一个实例和一个逻辑核绑定,而要和一个物理核绑定,也就是说,把一个物理核的2个逻辑核都用上。
方案二:优化Redis源码
通过修改Redis源码,把子进程和后台线程绑到不同的CPU核上。