文章来源:SmartX知乎专栏
作者介绍:
@张凯(Kyle Zhang),SmartX 联合创始人 & CTO。SmartX 拥有国内最顶尖的分布式存储和超融合架构研发团队,是国内超融合领域的技术领导者。
——————————————————————————
过去半年阅读了 30 多篇论文,坚持每 1~2 周写一篇 Newsletter,大部分都和存储相关。今天在这里进行一个总结,供大家作为了解存储技术热点和趋势的参考。本文包含了全新的技术领域,如 Open-Channel SSD,Machine Learning for Systems;也包含老话题的新进展,如 NVM,LSM-Tree,Crash Consistency;以及工业界的进展。
Open-Channel SSD
Open-Channel SSD 在国内关注的人比较少。和传统 SSD 相比,Open-Channel SSD 仅提供一个最简化的 SSD,只包含 NAND 芯片和控制器,并不包含 Flash Translation Layer(FTL)。原有 FTL 中的功能,例如 Logical Address Mapping,Wear Leveling,Garbage Collection 等,需要由上层实现,可能是操作系统,也可能是某个应用程序。也就是说,Open-Channel SSD 提供了一个裸 SSD,用户可以根据自己的需要设计和实现自己的 FTL,以达到最佳效果。
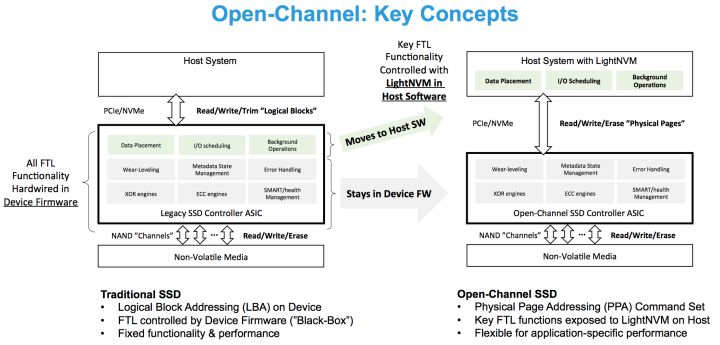
我们通过一个具体场景来描述 Open-Channel SSD 的价值。RocksDB 作为一个单机存储引擎,被广泛应用在很多分布式存储的场景中。RocksDB 的数据存储采用 LSM-Tree + WAL 的方式,其中,LSM-Tree 用于存储数据和索引,WAL 用于保证数据写入的完整性(Data Integrity)。由于目前在 RocksDB 的实现中,LSM-Tree 中的 SSTable 和 WAL 都是文件系统上的一个文件,所以数据写入 WAL 的过程中,也会触发文件系统的数据保护机制,例如 Journaling。而文件系统在将数据写入 Journal 时,也会触发 SSD FTL 层的数据保护机制。所以,一次 RocksDB 的写请求会经过三个 IO 子系统:RocksDB,File System,FTL。每一层子系统为了保证数据完整性,都会产生写放大(Write Amplification),使得一次写入被放大几十甚至上百倍。这个现象可以被形象的描述为『Log-On-Log』的现象。
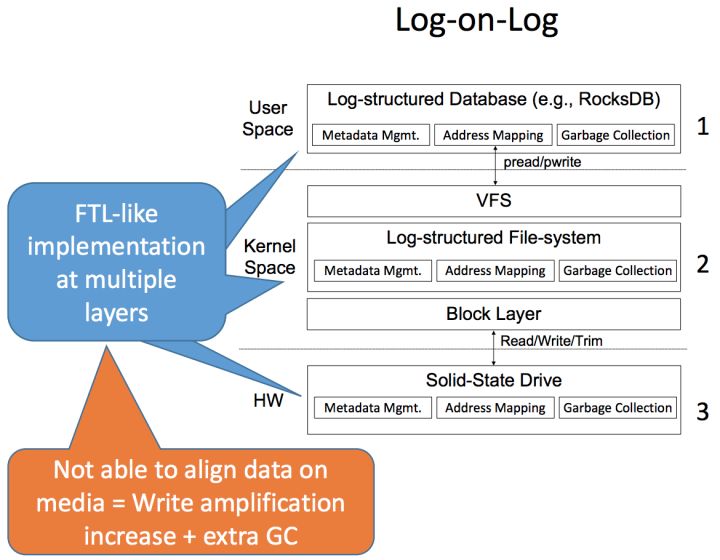
而实际上,对于 RocksDB 的 WAL,以及文件系统的 Journal,实际上都是临时性的写入,并不需要底层系统额外的数据保护机制。Open-Channel SSD 的出现提供了打破这个现象的机会,如果在 RocksDB 可以绕过文件系统层以及 FTL,则可以将三层 Log 合并为一层,避免写入放大,最大化发挥 SSD 的性能。
除了避免写放大之外,在 LSM-Tree 数据结中,由于 SSTable 是只读不可修改的,而 SSD 的 Block 也是只读的(如果要写入必须先擦写),那么 RocksDB 可以利用 SSD 的这个特点,让 SSTable 与 Block 对齐,将 LSM-Tree 中的删除 SSTable 操作与 SSD 的 Block 回收操作合并,避免 SSD Block 回收时产生的数据拷贝操作,避免 GC 对性能产生影响。在 『An Efficient Design and Implementation of LSM-Tree based Key-Value Store on Open-Channel SSD』 中,就实现了将 LevelDB 直接运行在 Open-Channel SSD 上。
除了避免写放大,Open-Channel SSD 还提供了实现 IO Isolation 的可能性。由于 SSD 的物理特性,SSD 的性能和数据的物理布局紧密相关。SSD 的性能来自于每一个 NAND 芯片的性能的总和。每一个 NAND 芯片提供的 IO 性能很低,但由于 NAND 芯片之间可以进行并行化,这使得 SSD 的整体性能非常高。换句话说,数据的布局决定了 IO 性能。然而由于传统的 SSD 上运行了 FTL,FTL 不仅会对数据的布局进行重映射,同时在后台还会运行 GC 任务,这使得 SSD 的性能是无法预测的,也无法进行隔离。Open-Channel SSD 将底层信息暴露给上层应用,通过将数据放置在不同的 NAND 芯片上,可以在物理层面达到数据分布隔离,同时也就打到了性能的隔离的效果。
为了方便的管理和操作 Open-Channel SSD,LightNVM 应运而生。LightNVM 是在 Linux Kernel 中一个针对 Open-Channel SSD 的 Subsystem。LightNVM 提供了一套新的接口,用于管理 Open-Channel SSD,以及执行 IO 操作。为了和 Kernel 中现有的 IO 子系统协同工作,还存在 pblk(Physical Block Device)层。他在 LightNVM 的基础上实现了 FTL 的功能,同时对上层暴露传统的 Block 层接口,使得现有的文件系统可以通过 pblk 直接运行在 Open-Channel SSD 上。2017 年 FAST 上的一篇 paper:『LightNVM: The Linux Open-Channel SSD Subsystem』专门介绍了 LightNVM。

目前 LightNVM 已经被合并入 Kernel 的主线。而对于用户态的程序来说,可以通过 liblightnvm 操作 Open-Channel SSD。
2018 年 1 月,Open-Channel SSD 发布了 2.0 版本的标准。但无论是 Open-Channel SSD,还是 LightNVM 都还处于非常早期的阶段,目前在市面上很难见到 Open-Channel SSD,不适合直接投入到生产中。尽管如此,Open-Channel SSD 和 Host based FTL 带来的好处是非常巨大的。对于追求极致存储性能的场景,在未来很可能会采用 Open-Channel SSD + LightNVM 的实现方式。
Non-volative Memory(NVM)
NVM,或者 PM(persistent memory),SCM(storage class memory),实际上都是一个意思,指的都是非易失性内存。NVM 在学术界火了很多年了, 相关的研究在不断向前推进。
一直以来,由于 2:8 定律的特性,计算机系统的存储一直是采用分层的结构,从上到下依次是 CPU Cache,DRAM,SSD,HDD。 其中,CPU Cache 和 DRAM 是易失性的(volatile),SSD 和 HDD 是非易失性的(non-volatile)。尽管 SSD 的速度远高于 HDD,但和 DDR 相比,还是有一定的差距。SSD 提供 10us 级别的响应时间,而 DRAM 只有 ns 级别,这中间有一万倍的差距。由于 DRAM 和 SSD 之间巨大的性能差距,使得应用程序需要非常仔细的设计 IO 相关的操作,避免 IO 成为系统的性能瓶颈。
而 NVM 的出现弥补了这个差距。NVM 在保持非易失性的前提下,将响应时间降低到 10ns 级别,同时单位容量价格低于 DRAM。此外,NVM 是按字节访问(byte-addressable),而不像磁盘按照块(Block)访问。NVM 的出现打破了传统的存储层次,将对软件架构设计产生巨大的影响。
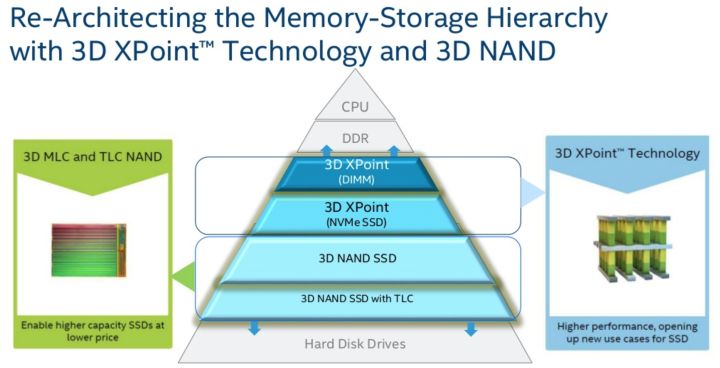
NVM 看上去很美好,但目前并不能像内存或磁盘一样,做到即插即用。在传统的操作系统中,Virtual Memory Manager(VMM)负责管理易失性内存,文件系统负责管理存储。而 NVM 既像内存一样可以通过字节访问,又像磁盘一样具有非易失性的特点。使用 NVM 的方式主要有两种:
将 NVM 当做事务性内存(Persistant Transactional Memory)使用,包括采用 Redo Logging,Undo Logging,以及 Log-Structured 等管理方式。将 NVM 当做磁盘使用,提供块以及文件的接口。例如在 Linux 中引入的 Direct Access(DAX),可以将对现有的文件系统进行扩展,使得其可以运行在 NVM 上,例如 Ext4-DAX。也有类似于 PMFS,NOVA 等专门为 NVM 定制的文件系统。
面向 NVM 进行编程和面向传统的内存或磁盘编程是非常不同,这里我们举一个非常简单的例子。例如,有一个函数用于执行双链表插入操作:
voidlist_add_tail(structcds_list_head*newp,structcds_list_head*head){head->prev->next=newp;newp->next=head;newp->prev=head->prev;head->prev=newp;}
然而对于 NVM 来说,由于是非易失性的,假设在执行到函数的第一行后发生了断电,当系统恢复后,链表处于一个异常且无法恢复的状态。同时,由于 CPU 和 NVM 之间还有 CPU Cache 作为缓存,以及 CPU 执行具有乱序执行的特性,所以 NVM 需要使用特殊的编程模型,也就是 NVM Programming Model。通过显示的指定 Transaction,达到原子性操作的语义,保证当系统恢复时,不会产生中间状态。
在分布式场景下,如果要充分发挥 NVM 的性能,就必须和 RDMA 结合。由于 NVM 的超高的性能,Byte Addressable 的访问特性,以及 RDMA 的访问方式,使得分布式的 NVM + RDMA 需要全新的架构设计,包括单机数据结构,分布式数据结构,分布式一致性算法等等。在这方面,清华计算机系高性能所去年发表的 Octopus 提供了一个思路,通过 NVM + RDMA 实现了分布式文件系统,同时在自己实现一套基于 RDMA 的 RPC 用于进行节点间的通信。
然而尴尬的是,尽管学术界在 NVM 上已经研究了数十年,但在工业界目前还没有可以大规模商用的 NVM 产品,大家还只能基于模拟器进行研究。Intel 和 Micro 在 2012 年合作一起研发 3D XPoint 技术,被认为是最接近能商用的 NVM 产品。Intel 在 2017 年发布了基于 3D XPoint 技术的磁盘产品 Optane,而 NVM 产品(代号 Apache Pass)还没有明确的发布时间。
然而即使 NVM 产品面世,由于 NVM 的价格和容量的限制,以及复杂的编程模式,在实际生产中很少会出现纯 NVM 的场景,更多的还是 tiering 的形式,也就是 NVM + SSD + HDD 的组合。在这个方面,2017 SOSP 上的一篇论文 Strata 也提供了一个不错的思路。
Machine Learning for Systems
去年 Jeff Dean 所在的 Google Brain 团队发表了一篇非常重要的论文『The Case for Learned Index Structures』。可以说从这篇文章开始,系统领域展开了一个新的方向,Machine Learning 与系统相结合。不得不赞叹 Jeff Dean 对计算机科学的影响力。
这篇文章,以及 Jeff Dean 在 NIPS17 ML Systems Workshop 上的 talk,都释放出了一个很强的信号,计算机系统中包含了大量的 Heuristics 算法,用于做各种各样的决策,例如 TCP 窗口应该设置为多大,是否应该对数据进行缓存,应该调度哪一个任务等等。而每一种算法都存在性能,资源消耗,错误率,以及其他方面的 Tradeoff,需要大量的人工成本进行选择和调优。而这些正是Machine Learning 可以发挥的地方。
在 『The Case for Learned Index Structures』 文章中,作者提到了一个典型的场景,数据库的索引。传统的索引通常采用 B 树,或 B 树的变种。然而这些数据结构通常是为了一个通用的场景,以及最差的数据分布而进行设计的,并没有考虑到实际应用中数据分布情况。对于很多特殊的数据分布场景,B 树并不能够达到最优的时间和空间复杂度。为了达到最佳效果,需要投入大量的人力进行数据结构的优化。同时,由于数据的分布在不断的变化,调优的工作也是持续不断的。作者提出的的 Learned Index,则是通过与 Machine Learning 技术结合,避免人工调优的开销。
在这篇文章中,作者把索引数据结构当做一个 Model,这个 Model 的输入是一个 Key,输出是这个 Key 对应的 Value 在磁盘中的位置。而 B 树或其他的数据结构只是实现这个 Model 的一种方式,而这个 Model 也可以存在其他的实现形式,例如神经网络。

和 B 树相比,神经网络具有很大的优势:
由于不需要在内存中保存 key,所以占用内存空间极小。尤其当索引量巨大时,避免产生磁盘访问。由于避免了树遍历引入的条件判断,查找速度更快
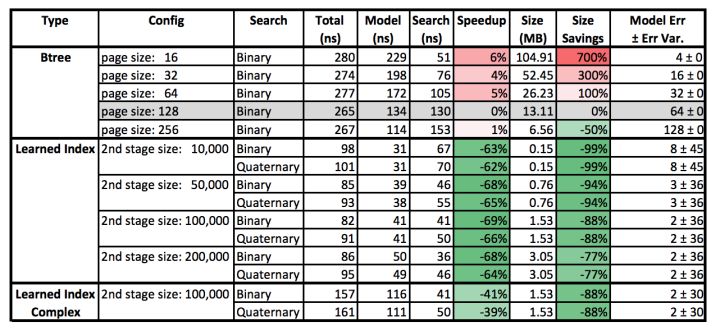
通过进行离线的模型训练,牺牲一定的计算资源,可以达到节省内存资源,以及提高性能的效果。
当然,这种方法也存在一定的局限性。其中最重要的一点,就是 Learned Index 只能索引固定数据分布的数据。当有数据插入时导致数据分布发生了变更,原有的模型就会失效。解决的方案是对于新增的数据,依然采用传统的数据结构进行索引,Learned Index 只负责索引原有数据。当新增数据积累到一定程度时,将新数据与原有数据进行合并,并根据新的数据分布训练出新的模型。这种方法是很可行的,毕竟和新增数据量相比,全量数据是非常大的。如果能对全量数据的索引进行优化,那应用价值也是巨大的。
尽管存在一定的局限性,Learned Index 还是有很多适用的场景,例如 Google 已经将其应用在了 BigTable 中。相信 Learned Index 只是一个开端,未来会有越来越多的 System 和 Machine Learning 结合的工作出现。
LSM-Tree 优化
LSM-Tree 是 LevelDB,以及 LevelDB 的变种,RocksDB,HyperDB 等单机存储引擎的核心数据结构。
LSM-Tree 本身的原理我们不过多介绍。目前 LSM-Tree 最大的痛点是读写放大,这使得性能往往只能提供裸硬件的不到 10%。所以关于解决 LSM-Tree 读写放大问题成为近些年研究的热点。
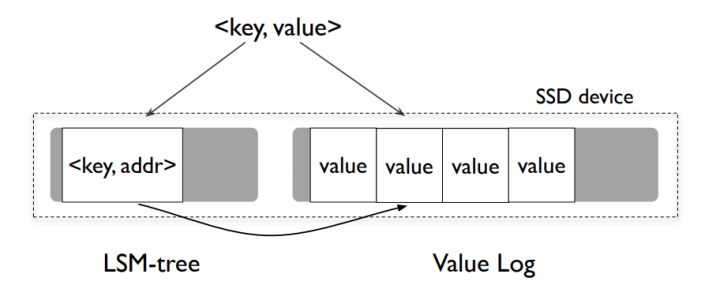
在 2016 年 FAST 会议上发表的论文 WiscKey 提出了将 Key 与 Value 分开存放的方法。传统 LSM-Tree 将 Key 和 Value 相邻存放,保证 Key 和 Value 在磁盘上都是有序的。这提高了 Range Query 的效率。然而,当进行 Compaction 时,由于需要同时操作 Key 和 Value,所以造成了较大读写比例放大。而在 WiscKey 中,通过将 Key 和 Value 分开存放,Key 保持 LSM-Tree 结构,保证 Key 在磁盘上的有序性,而 Value 使用所谓 『Value Log』 结构,很像 Log-Structured File System 中的一个 Segment。通过在 Key 中保存 Value 在磁盘上的位置,使得可以通过 Key 读取到 Value。由于 LSM-Tree 中只保存 Key,不保存 Value,且 Key 的大小通常远小于 Value 的大小,所以 WiscKey 中的 LSM-Tree 的大小远小于传统 LSM-Tree 的大小,因此 Compaction 引入的读写放大可以控制在非常小的比例。WiscKey 的缺点是牺牲了 Range Query 的性能。由于相邻 Key 的 Value 在磁盘上并没有存在相邻的位置,WiscKey 中对连续的 Key 读取被转化成随机磁盘读取操作。而作者通过将预读(Prefetching)IO 并行化的方式,尽可能降低对顺序读性能的影响。
而在 2017 年 SOSP 上发表的论文 PebblesDB 提出了另外一种思路。在传统 LSM-Tree 中,每一层由多个 SSTable 组成,每一个 SSTable 中保存了一组排好序 Key-Value,相同层的 SSTable 之间的 Key 没有重叠。当进行 Compaction 时,上层的 SSTable 需要与下层的 SSTable 进行合并,也就是将上层的 SSTable 和下层的 SSTable 读取到内存中,进行合并排序后,组成新的 SSTable,并写回到磁盘中。由于 Compaction 的过程中需要读取和写入下层的 SSTable,所以造成了读写放大,影响应能。
PebblesDB 将 LSM-Tree 和 Skip-List 数据结构进行结合。在 LSM-Tree 中每一层引入 Guard 概念。 每一层中包含多个 Guard,Guard 和 Guard 之间的 Key 的范围是有序的,且没有重叠,但 Guard 内部包含多个 SSTable,这些 SSTable 的 Key 的范围允许重叠。
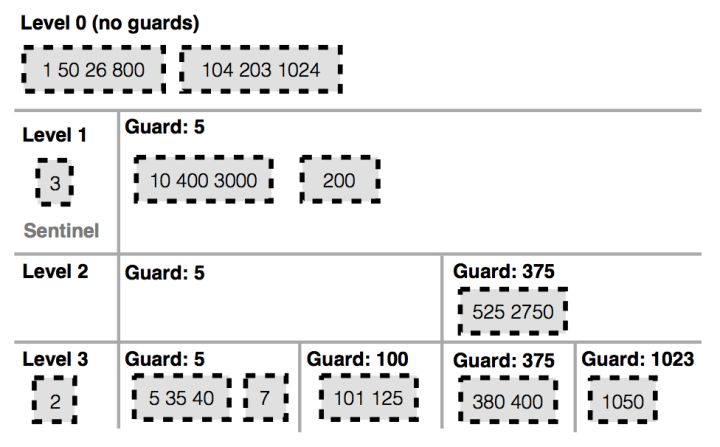
当需要进行 Compaction 时,只需要将上层的 SSTable 读入内存,并按照下层的 Guard 将 SSTable 切分成多个新的 SSTable,并存放到下层对应的 Guard 中。在这个过程中不需要读取下层的 SSTable,也就在一定程度上避免了读写放大。作者将这种数据结构命名为 Fragemented Log-Structured Tree(FLSM)。PebblesDB 最多可以减低 6.7 倍的写放大,写入性能最多提升 105%。
和 WiscKey 类似,PebblesDB 也会多 Range Query 的性能造成影响。这是由于 Guard 内部的 SSTable 的 Key 存在重叠,所以在读取连续的 Key 时,需要同时读取 Guard 中所有的 SSTable,才能够获得正确的结果。
WiscKey 和 PebblesDB 都已经开源,但在目前最主流的单机存储引擎 LevelDB 和 RocksDB 中,相关优化还并没有得到体现。我们也期待未来能有更多的关于 LSM-Tree 相关的优化算法出现。
Crash Consistency
Crash Consistency 的意思是,存储系统可以在故障发生后,保证系统数据的正确性以及数据,元数据的一致性。可以说 Crash Consistency 是存储领域永恒不变的话题。
早些年大家热衷于通过各种方法在已实现的文件系统中寻找 Bug,而这两年构造一个新的 Bug Free 的文件系统成为热门的方向。在这方面最早做出突破的是 MIT 的团队的 FSCQ。FSCQ 通过 Coq 作为辅助的形式化验证工具,在 Crash Hoare Logic 的基础上,实现了一个被证明过 Crash Safty 的文件系统。
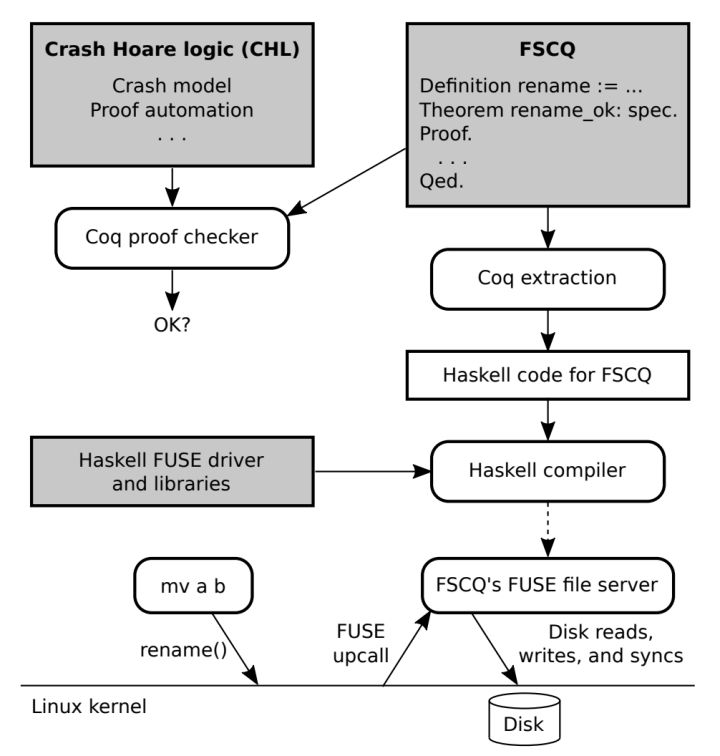
然而使用 Coq 的代价是需要人工手动完成证明过程,这使得完成一个文件系统的工作量被放大了几倍,例如 FSCQ 的证明过程花费了 1.5 年。
而 Washington 大学提出的 Yggdrasil 则基于 Z3,将文件系统证明过程自动化,也就是最近非常流行的『Push-Button Verification』 的方法。

值得注意的是,无论是 FSCQ 还是 Yggdrasil 都存在着巨大的局限性,例如不支持多线程访问,文件系统功能并不完备,性能较弱,以及代码生成过程中依赖一些没有被验证过的工具等等。我们距离构建一个在通用场景下可以完全替代已有文件系统(如 ext4)还有很长的路要走。这也依赖于形式化验证方面的技术突破。
工业界进展
随着虚拟化技术的成熟和普及,存储的接入端逐渐从 HBA 卡或传统操作系统,转变为 Hypervisor。在 Linux KVM 方面,随着存储性能逐渐提高,原有的 virtio 架构逐渐成为了性能瓶颈,vhost 逐渐开始普及。所谓 vhost 就是把原有 Qemu 对于 IO 设备模拟的代码放到了 Kernel 中,包含了 vhost-blk,以及 vhost-net。由 Kernel 直接将 IO 请求发给设备。通过减少上下文的切换,避免额外的性能开销。
在容器方面,随着 K8S 的应用和成熟,在 K8S 的存储方面也诞生了一些新的项目。比如 rook.io 是基于 K8S 的编排工具。而 K8S 本身也发布了 Container Storage Interface(CSI),用于第三方存储厂商更好的开发 K8S 的存储插件。未来也会看到越来越多的存储厂商对 K8S 进行支持。
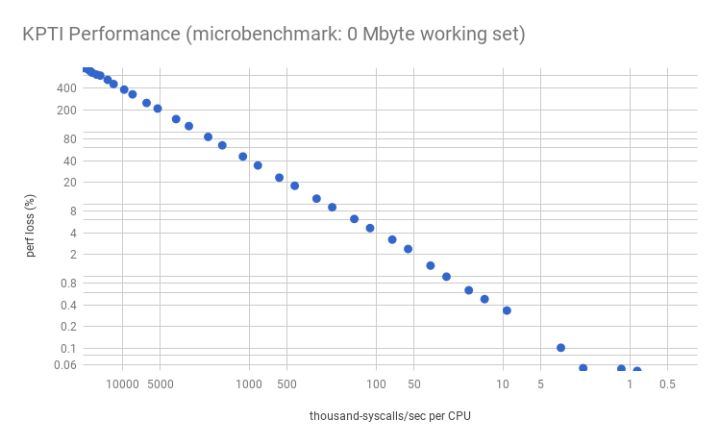
2017 年 Linux Kernel 共发布了 5 个版本,从 4.10 到 4.14,目前最新的版本是 4.15。其中存储相关比较值得注意的变化包括:AIO 改进,Block Layer 错误处理改进,基于 MQ 的调度器 Kyber 等等。然而比较悲伤的消息是,为了修复 Meltdown 和 Spectrue 漏洞,Kernel 引入了 Kernel Page Table Isolation(KPTI)技术,这导致系统调用和上下文切换的开销变得更大。Brendan Gregg 在他的博客中详细分析了 KPTI 对性能产生的影响。对于系统调用与上下文切换越频繁的应用,对性能的影响越大。也就是说,IO 密集型的应用将受到比较大的影响,而计算密集型的应用则影响不大。
在企业级存储方面,去年有很多存储厂商都开始向纯软件厂商进行转型,包括 Nutanix,Kaminario 以及 E8 等等。向软件化转型并不是处于技术的原因,而是商业的考虑。考虑到 Dell 和 EMC 的合并,存储硬件的利润率必定会不断下降。软件化最大的好处,就是可以提升财务报表中的利润率,使得公司的财务状况更加健康,也避免了和 Dell EMC 的存储硬件发生竞争。

在资本市场方面,2017 年可以说是波澜不惊。上图是 2017 年存储行业发生的并购案。其中 Toshiba Memory 被收购的案件是存储行业历史上第三大收购案(第一名是 Dell 收购 EMC)。
总结
以上是作者对当前存储热点和趋势的不完整的总结。希望帮助读者对存储领域增加一点点了解,或者是对存储技术产生一点点的兴趣。也欢迎大家把自己感兴趣的话题写在评论里,我们将在后面尽可能的为大家进行介绍。
顺便广告一下,SmartX 是全球技术领先的分布式存储厂商,如果想在存储领域做出一番事业的话,欢迎加入 SmartX。