强化学习概况
正如在前面所提到的,强化学习是指一种计算机以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使程序获得最大的奖赏,强化学习不同于连督学习,区别主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统如何去产生正确的动作。唯一的目的是最大化效率和/或性能。算法对正确的决策给予奖励,对错误的决策给予惩罚,如下图所示:
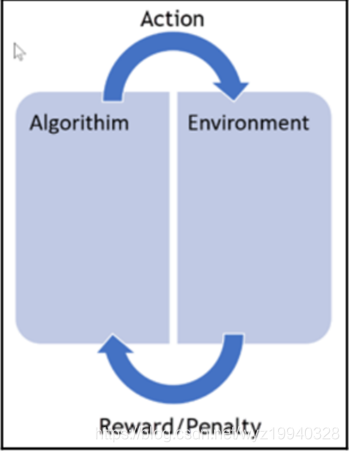
持续的训练是为了不断提高效率。这里的重点是性能,这意味着我们需要,在看不见的数据和算法已经学过的东西,之间找到一种平衡。该算法将一个操作应用到它的环境中,根据它所做的行为接受奖励或惩罚,不断的重复这个过程,等等。
接下来让我们看一个程序,概念是相似的,尽管它的规模和复杂性很低。想象一下,是什么让自动驾驶的车辆从一个地点移动到了另一个点。
让我们看看我们的应用程序:
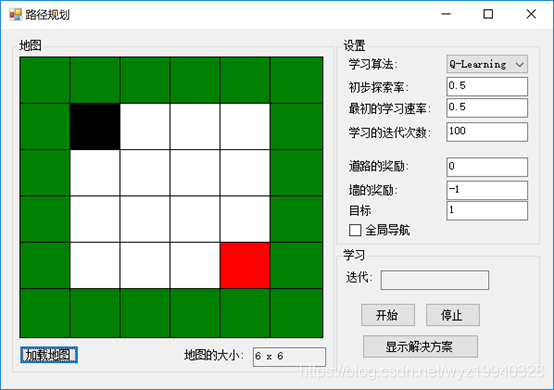
在这里,可以看到我们有一个非常基本的地图,一个没有障碍,但有外部限制的墙。黑色块(start)是我们的对象,红色块(stop)是我们的目标。在这个应用程序中,我们的目标是让我们的对象在墙壁以内到达目标位置。如果我们的下一步把我们的对象放在一个白色的方块上,我们的算法将得到奖励。如果我们的下一步行动超出墙壁的围地范围,我们将受到惩罚。在这个例子中,它的路径上绝对没有障碍,所以我们的对象应该能够到达它的目的地。问题是:它能多快学会?
下面是另一个比较复杂的地图示例:
学习类型
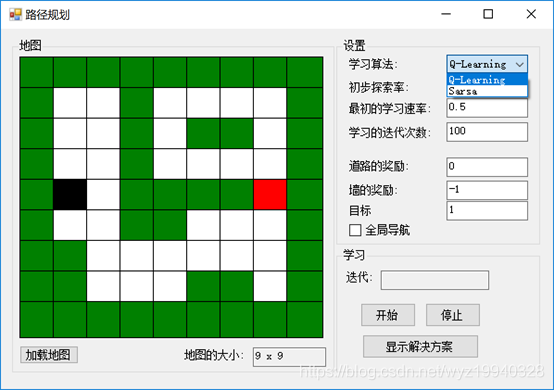
在应用程序的右边是我们的设置,如下面的屏幕截图所示。我们首先看到的是学习算法。在这个应用中,我们将处理两种不同的学习算法,Q-learning和state-action-reward-state-action (SARSA)。让我们简要讨论一下这两种算法。
Q-learning
Q-learning可以在没有完全定义的环境模型的情况下,识别给定状态下的最优行为(在每个状态中值最高的行为)。它还擅长处理随机转换和奖励的问题,而不需要调整或适应。
以下是Q-learning的数学表达式:

如果我们提供一个非常高级的抽象示例,可能更容易理解。
程序从状态1开始。然后它执行动作1并获得奖励1。接下来,它四处寻找状态2中某个行为的最大可能奖励是多少;然后使用它来更新动作1的值等等。
SARSA
SARSA的工作原理是这样的:
1. 程序从状态1开始。
2. 然后它执行动作1并获得奖励1。
3. 接下来,它进入状态2,执行动作2,并获得奖励2。
4. 然后,程序返回并更新动作1的值。
这Q-learning算法的不同之处在于找到未来奖励的方式。
Q-learning使用状态2中奖励最高的动作的值,而SARSA使用实际动作的值。
这是SARSA的数学表达式:
![]()
运行我们的应用程序
现在,让我们开始使用带有默认参数的应用程序。只需点击开始按钮,学习就开始了。完成后,您将能够单击Show Solution按钮,学习路径将从头到尾播放。
点击Start开始学习阶段,一直到黑色物体达到目标:
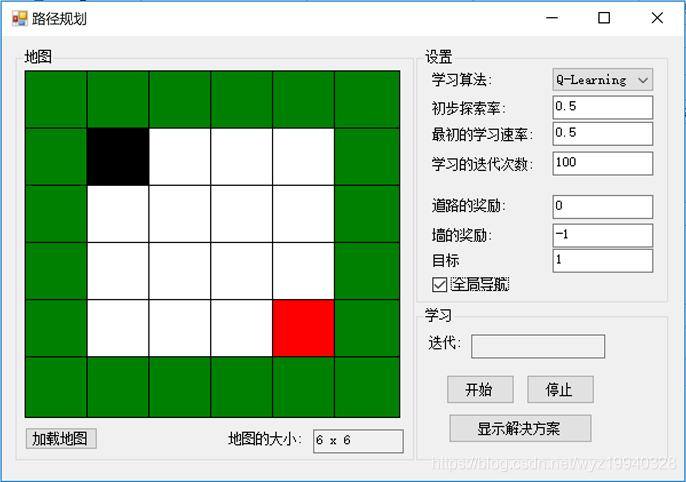
对于每个迭代,将评估不同的对象位置,以及它们的操作和奖励。一旦学习完成,我们可以单击Show Solution按钮来重播最终的解决方案。完成后,黑色对象将位于红色对象之上:
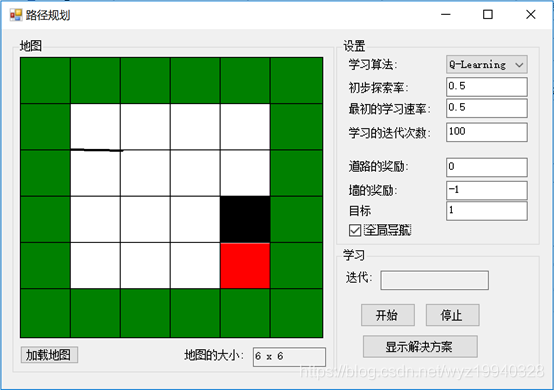
现在让我们看看应用程序中的代码。有两种我们之前强调过的学习方法。
Q-learning是这样的:
/// <summary> /// Q-Learning 线程 /// </summary> private void QLearningThread() { //迭代次数 int iteration = 0; TabuSearchExploration tabuPolicy = (TabuSearchExploration)qLearning.ExplorationPolicy; EpsilonGreedyExploration explorationPolicy = (EpsilonGreedyExploration)tabuPolicy.BasePolicy; while ((!needToStop)&&(iteration<learningIterations)) { explorationPolicy.Epsilon = explorationRate - ((double)iteration / learningIterations) * explorationRate; qLearning.LearningRate = learningRate - ((double)iteration / learningIterations) * learningRate; tabuPolicy.ResetTabuList(); var agentCurrentX = agentStartX; var agentCurrentY = agentStartY; int steps = 0; while ((!needToStop)&& ((agentCurrentX != agentStopX) || (agentCurrentY != agentStopY))) { steps++; int currentState= GetStateNumber(agentCurrentX, agentCurrentY); int action = qLearning.GetAction(currentState); double reward = UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, action); int nextState = GetStateNumber(agentCurrentX, agentCurrentY); // 更新对象的qLearning以设置禁忌行为 qLearning.UpdateState(currentState, action, reward, nextState); tabuPolicy.SetTabuAction((action + 2) % 4, 1); } System.Diagnostics.Debug.WriteLine(steps); iteration++; SetText(iterationBox, iteration.ToString()); } EnableControls(true); }
SARSA学习有何不同?让我们来看看SARSA学习的while循环,并理解它:
/// <summary> /// Sarsa 学习线程 /// </summary> private void SarsaThread() { int iteration = 0; TabuSearchExploration tabuPolicy = (TabuSearchExploration)sarsa.ExplorationPolicy; EpsilonGreedyExploration explorationPolicy = (EpsilonGreedyExploration)tabuPolicy.BasePolicy; while ((!needToStop) && (iteration < learningIterations)) { explorationPolicy.Epsilon = explorationRate - ((double)iteration / learningIterations) * explorationRate; sarsa.LearningRate = learningRate - ((double)iteration / learningIterations) * learningRate; tabuPolicy.ResetTabuList(); var agentCurrentX = agentStartX; var agentCurrentY = agentStartY; int steps = 1; int previousState = GetStateNumber(agentCurrentX, agentCurrentY); int previousAction = sarsa.GetAction(previousState); double reward = UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, previousAction); while ((!needToStop) && ((agentCurrentX != agentStopX) || (agentCurrentY != agentStopY))) { steps++; tabuPolicy.SetTabuAction((previousAction + 2) % 4, 1); int nextState = GetStateNumber(agentCurrentX, agentCurrentY); int nextAction = sarsa.GetAction(nextState); sarsa.UpdateState(previousState, previousAction, reward, nextState, nextAction); reward = UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, nextAction); previousState = nextState; previousAction = nextAction; } if (!needToStop) { sarsa.UpdateState(previousState, previousAction, reward); } System.Diagnostics.Debug.WriteLine(steps); iteration++; SetText(iterationBox, iteration.ToString()); } // 启用设置控件 EnableControls(true); }
最后一步,看看如何使解决方案具有动画效果。我们需要这样才能看到我们的算法是否实现了它的目标。
代码如下:
TabuSearchExploration tabuPolicy; if (qLearning != null) tabuPolicy = (TabuSearchExploration)qLearning.ExplorationPolicy; else if (sarsa != null) tabuPolicy = (TabuSearchExploration)sarsa.ExplorationPolicy; else throw new Exception(); var explorationPolicy = (EpsilonGreedyExploration)tabuPolicy?.BasePolicy; explorationPolicy.Epsilon = 0; tabuPolicy?.ResetTabuList(); int agentCurrentX = agentStartX, agentCurrentY = agentStartY; Array.Copy(map, mapToDisplay, mapWidth * mapHeight); mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3;
这是我们的while循环,所有神奇的事情都发生在这里!
while (!needToStop) { cellWorld.Map = mapToDisplay; Thread.Sleep(200); if ((agentCurrentX == agentStopX) && (agentCurrentY == agentStopY)) { mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3; agentCurrentX = agentStartX; agentCurrentY = agentStartY; cellWorld.Map = mapToDisplay; Thread.Sleep(200); } mapToDisplay[agentCurrentY, agentCurrentX] = 0; int currentState = GetStateNumber(agentCurrentX, agentCurrentY); int action = qLearning?.GetAction(currentState) ?? sarsa.GetAction(currentState); UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, action); mapToDisplay[agentCurrentY, agentCurrentX] = 2; }
让我们把它分成更容易消化的部分。我们要做的第一件事就是建立禁忌政策。如果您不熟悉tabu搜索,请注意,它的目的是通过放松其规则来提高本地搜索的性能。在每一步中,如果没有其他选择(有回报的行动),有时恶化行动是可以接受的。
此外,还设置了prohibition (tabu),以确保算法不会返回到以前访问的解决方案。
TabuSearchExploration tabuPolicy; if (qLearning != null) tabuPolicy = (TabuSearchExploration)qLearning.ExplorationPolicy; else if (sarsa != null) tabuPolicy = (TabuSearchExploration)sarsa.ExplorationPolicy; else throw new Exception(); var explorationPolicy = (EpsilonGreedyExploration)tabuPolicy?.BasePolicy; explorationPolicy.Epsilon = 0; tabuPolicy?.ResetTabuList();
接下来,我们要定位我们的对象并准备地图。
int agentCurrentX = agentStartX, agentCurrentY = agentStartY; Array.Copy(map, mapToDisplay, mapWidth * mapHeight); mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3;
下面是我们的主执行循环,它将以动画的方式显示解决方案:
while (!needToStop) { cellWorld.Map = mapToDisplay; Thread.Sleep(200); if ((agentCurrentX == agentStopX) && (agentCurrentY == agentStopY)) { mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3; agentCurrentX = agentStartX; agentCurrentY = agentStartY; cellWorld.Map = mapToDisplay; Thread.Sleep(200); } mapToDisplay[agentCurrentY, agentCurrentX] = 0; int currentState = GetStateNumber(agentCurrentX, agentCurrentY); int action = qLearning?.GetAction(currentState) ?? sarsa.GetAction(currentState); UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, action); mapToDisplay[agentCurrentY, agentCurrentX] = 2; }
汉诺塔游戏
河内塔由三根杆子和最左边的几个按顺序大小排列的圆盘组成。目标是用最少的移动次数将所有磁盘从最左边的棒子移动到最右边的棒子。
你必须遵守的两条重要规则是,一次只能移动一个磁盘,不能把大磁盘放在小磁盘上;也就是说,在任何棒中,磁盘的顺序必须始终是从底部最大的磁盘到顶部最小的磁盘,如下所示:

假设我们使用三个磁盘,如图所示。在这种情况下,有33种可能的状态,如下图所示:
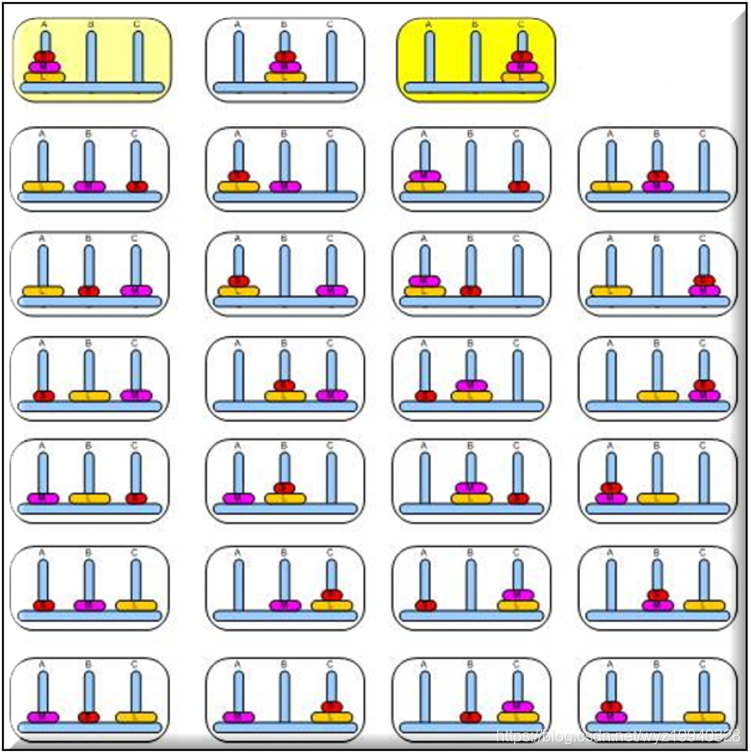
河内塔谜题中所有可能状态的总数是3的磁盘数次幂。

其中||S||是集合状态中的元素个数,n是磁盘的个数。
在我们的例子中,我们有3×3×3 = 27个圆盘在这三根棒上分布的唯一可能状态,包括空棒;但是两个空棒可以处于最大状态。
定义了状态总数之后,下面是我们的算法从一种状态移动到另一种状态的所有可能操作:
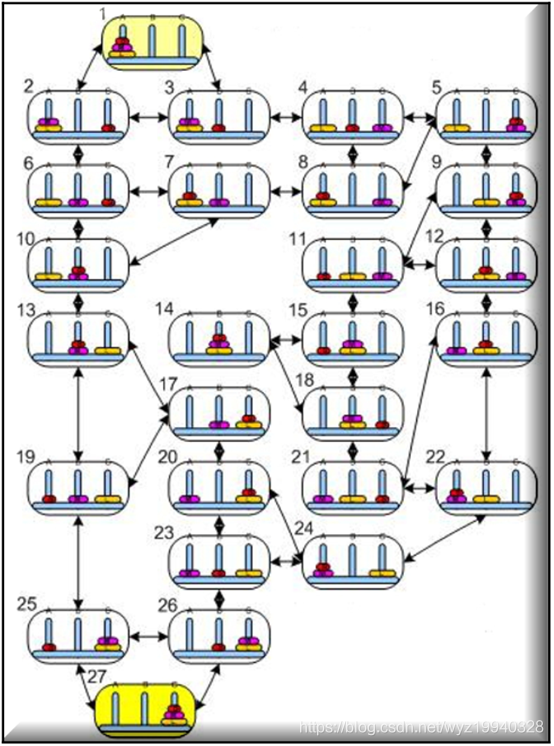
这个谜题的最小可能步数是:

磁盘的数量是n。
Q-learning算法的正式定义如下:
在这个Q-learning算法中,我们使用了以下变量:
- Q矩阵:一个二维数组,首先对所有元素填充一个固定值(通常为0),用于保存所有状态下的计算策略;也就是说,对于每一个状态,它持有对各自可能的行动的奖励。
- 折扣因子:决定了对象如何处理奖励的政策。当贴现率接近0时,只考虑当前的报酬会使对象变得贪婪,而当贴现率接近1时,会使对象变得更具策略性和前瞻性,从而在长期内获得更好的报酬。
- R矩阵:包含初始奖励的二维数组,允许程序确定特定状态的可能操作列表。
我们应该简要介绍一下Q-learning Class的一些方法:
Init:生成所有可能的状态以及开始学习过程。
Learn:在学习过程中有顺序的步骤
InitRMatrix: 这个初始化奖励矩阵的值如下:
1. 0:在这种状态下,我们没有奖励。
2. 100:这是我们在最终状态下的最大奖励,我们想去的地方。
3. X:在这种情况下是不可能采取这种行动的。
TrainQMatrix: 包含Q矩阵的实际迭代值更新规则。完成后,我们希望得到一个训练有素的对象。
NormalizeQMatrix: 使Q矩阵的值标准化,使它们成为百分数。
Test: 提供来自用户的文本输入,并显示解决此难题的最佳最短路径。
让我们更深入地研究我们的TrainQMatrix的代码:
/// <summary> /// 训练Q矩阵 /// </summary> /// <param name="_StatesMaxCount">所有可能移动的个数</param> private void TrainQMatrix(int _StatesMaxCount) { pickedActions = new Dictionary<int, int>(); // 可用操作列表(基于R矩阵,其中包含从某个状态开始的允许的下一个操作,在数组中为0) List<int> nextActions = new List<int>(); int counter = 0; int rIndex = 0; // 3乘以所有可能移动的个数就有足够的集来训练Q矩阵 while (counter < 3 * _StatesMaxCount) { var init = Utility.GetRandomNumber(0, _StatesMaxCount); do { // 获得可用的动作 nextActions = GetNextActions(_StatesMaxCount, init); // 从可用动作中随机选择一个动作 if (nextActions != null) { var nextStep = Utility.GetRandomNumber(0, nextActions.Count); nextStep = nextActions[nextStep]; // 获得可用的动作 nextActions = GetNextActions(_StatesMaxCount, nextStep); // 设置从该状态采取的动作的索引 for (int i = 0; i < 3; i++) { if (R != null && R[init, i, 1] == nextStep) rIndex = i; } // 这是值迭代更新规则-折现系数是0.8 Q[init, nextStep] = R[init, rIndex, 0] + 0.8 * Utility.GetMax(Q, nextStep, nextActions); // 将下一步设置为当前步骤 init = nextStep; } } while (init != FinalStateIndex); counter++; } }
使用三个磁盘运行应用程序:
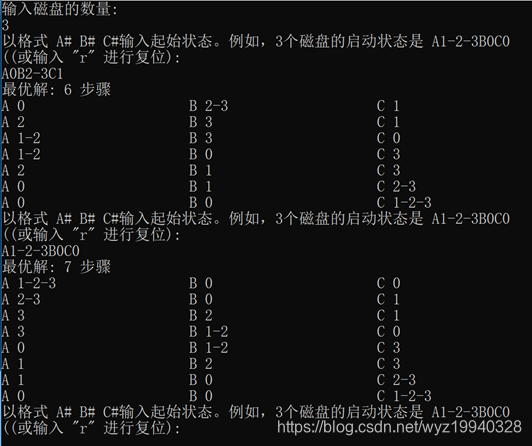
使用四个磁盘运行应用程序:
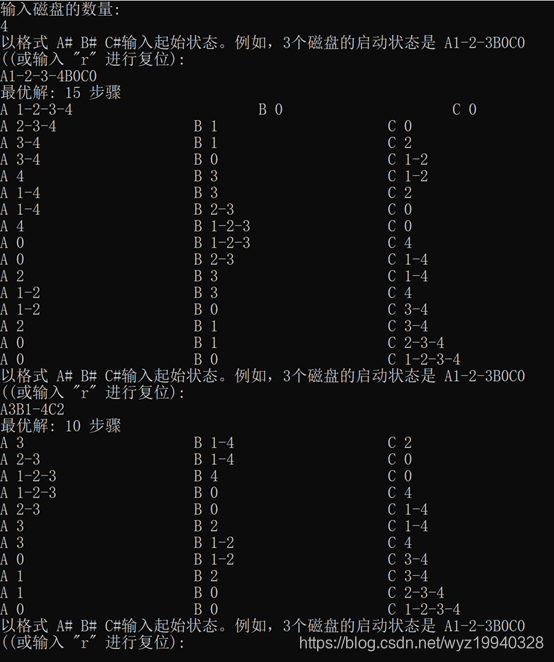
这里有7个磁盘。最佳移动步数是127,所以你可以看到解决方案可以多快地乘以可能的组合:
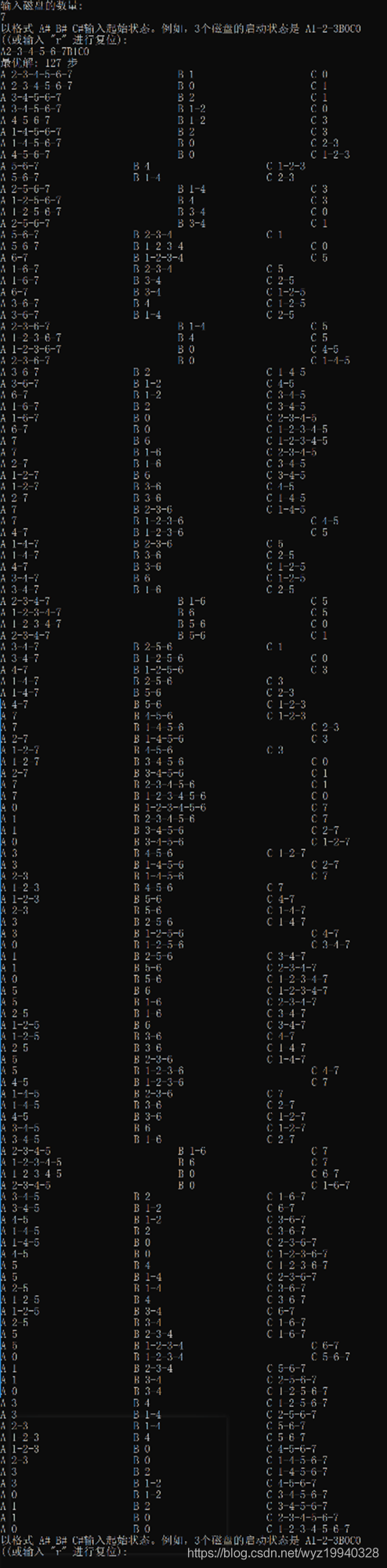
总结
这种形式的强化学习更正式地称为马尔可夫决策过程(Markov Decision Process, MDP)。MDP是一个离散时间随机控制的过程,这意味着在每个时间步,在状态x下,决策者可以选择任何可用的行动状态,这个过程将在下一步反应,随机移动到一个新的状态,给决策者一个奖励。进程进入新状态的概率由所选动作决定。因此,下一个状态取决于当前状态和决策者的行为。给定状态和操作,下一步完全独立于之前的所有状态和操作。