Spark2.1.0——Spark初体验
学习一个工具的最好途径,就是使用它。这就好比《*飞车》玩得好的同学,未必真的会开车,要学习车的驾驶技能,就必须用手触摸方向盘、用脚感受刹车与油门的力道。在IT领域,在深入了解一个系统的原理、实现细节之前,应当先准备好它的运行环境或者源码阅读环境。如果能在实际环境下安装和运行Spark,显然能够提升读者对于Spark的一些感受,对系统能有个大体的印象,有经验的工程师甚至能够猜出一些Spark在实现过程中采用的设计模式、编程模型。
考虑到大部分公司在开发和生产环境都采用Linux操作系统,所以笔者选用了64位的Linux。在正式安装Spark之前,先要找台好机器。为什么?因为笔者在安装、编译、调试的过程中发现Spark非常耗费内存,如果机器配置太低,恐怕会跑不起来。Spark的开发语言是Scala,而Scala需要运行在JVM之上,因而搭建Spark的运行环境应该包括JDK和Scala。
本文只介绍最基本的与Spark相关的准备工作,至于Spark在实际生产环境下的配置,则需要结合具体的应用场景进行准备。
安装JDK
自Spark2.0.0版本开始,Spark已经准备放弃对Java 7的支持,所以我们需要选择Java 8。我们还需要使用命令getconf LONG_BIT查看linux机器是32位还是64位,然后下载相应版本的JDK并安装。
下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/index.html。
配置环境:
cd ~ vim .bash_profile
添加如下配置:
exportJAVA_HOME=/opt/java exportPATH=$PATH:$JAVA_HOME/bin exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
输入以下命令使环境变量快速生效:
source .bash_profile
安装完毕后,使用java –version命令查看,确认安装正常,如图1所示。

图1 查看java安装是否正常
安装Scala
由于从Spark 2.0.0开始,Spark默认使用Scala 2.11来编译、打包,不再是以前的Scala 2.10,所以我们需要下载Scala 2.11。
下载地址:
http://www.scala-lang.org/download/
选择Scala 2.11的版本进行下载,下载方法如下:
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
移动到选好的安装目录,例如:
mv scala-2.11.8.tgz~/install/
进入安装目录,执行以下命令:
chmod 755scala-2.11.8.tgz tar -xzvfscala-2.11.8.tgz
配置环境:
cd ~ vim .bash_profile
添加如下配置:
export SCALA_HOME=$HOME/install/scala-2.11.8 export PATH=$SCALA_HOME/bin:$PATH
输入以下命令使环境变量快速生效:
source .bash_profile
安装完毕后键入scala,进入scala命令行以确认安装正常,如图2所示。

图2 进入Scala命令行
安装Spark
Spark进入2.0时代之后,目前一共有两个大的版本:一个是2.0.0,一个是2.1.0。本书选择2.1.0。
下载地址:
http://spark.apache.org/downloads.html
下载方法如下:
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.6.tgz
移动到选好的安装目录,如:
mv spark-2.1.0-bin-hadoop2.6.tgz~/install/
进入安装目录,执行以下命令:
chmod 755 spark-2.1.0-bin-hadoop2.6.tgz tar -xzvf spark-2.1.0-bin-hadoop2.6.tgz
配置环境:
cd ~ vim .bash_profile
添加如下配置:
export SPARK_HOME=$HOME/install/spark-2.1.0-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$PATH
输入以下命令使环境变量快速生效:
source .bash_profile
安装完毕后键入spark-shell,进入scala命令行以确认安装正常,如图3所示。
图3 执行spark-shell进入Scala命令行
既然已经介绍了如何准备好基本的Spark运行环境,现在是时候实践一下,以便于在使用过程中提升读者对于Spark最直接的感触!本文通过Spark的基本使用,让读者对Spark能有初步的认识,便于引导读者逐步深入学习。
运行spark-shell
在《Spark2.1.0——运行环境准备》一文曾经简单运行了spark-shell,并用下图进行了展示(此处再次展示此图)。
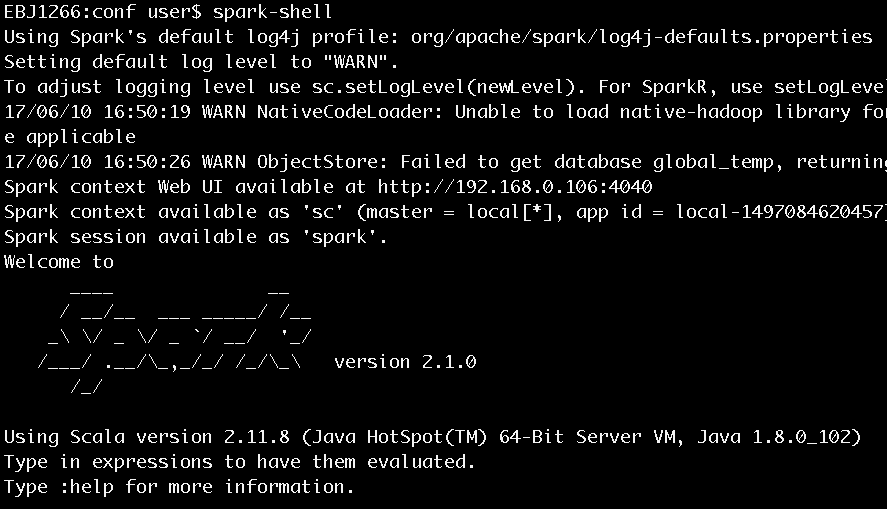
图4 执行spark-shell进入Scala命令行
图4中显示了很多信息,这里进行一些说明:
- 在安装完Spark 2.1.0后,如果没有明确指定log4j的配置,那么Spark会使用core模块的org/apache/spark/目录下的log4j-defaults.properties作为log4j的默认配置。log4j-defaults.properties指定的Spark日志级别为WARN。用户可以到Spark安装目录的conf文件夹下从log4j.properties.template复制一份log4j.properties文件,并在其中增加自己想要的配置。
- 除了指定log4j.properties文件外,还可以在spark-shell命令行中通过sc.setLogLevel(newLevel)语句指定日志级别。
- SparkContext的Web UI的地址是:http://192.168.0.106:4040。192.168.0.106是笔者安装Spark的机器的ip地址,4040是SparkContext的Web UI的默认监听端口。
- 指定的部署模式(即master)为local[*]。当前应用(Application)的ID为local-1497084620457。
- 可以在spark-shell命令行通过sc使用SparkContext,通过spark使用SparkSession。sc和spark实际分别是SparkContext和SparkSession在Spark REPL中的变量名,具体细节已在《Spark2.1.0——剖析spark-shell》一文有过分析。
由于Spark core的默认日志级别是WARN,所以看到的信息不是很多。现在我们将Spark安装目录的conf文件夹下的log4j.properties.template以如下命令复制出一份:
cp log4j.properties.template log4j.properties
并将log4j.properties中的log4j.logger.org.apache.spark.repl.Main=WARN修改为log4j.logger.org.apache.spark.repl.Main=INFO,然后我们再次运行spark-shell,将打印出更丰富的信息,如图5所示。
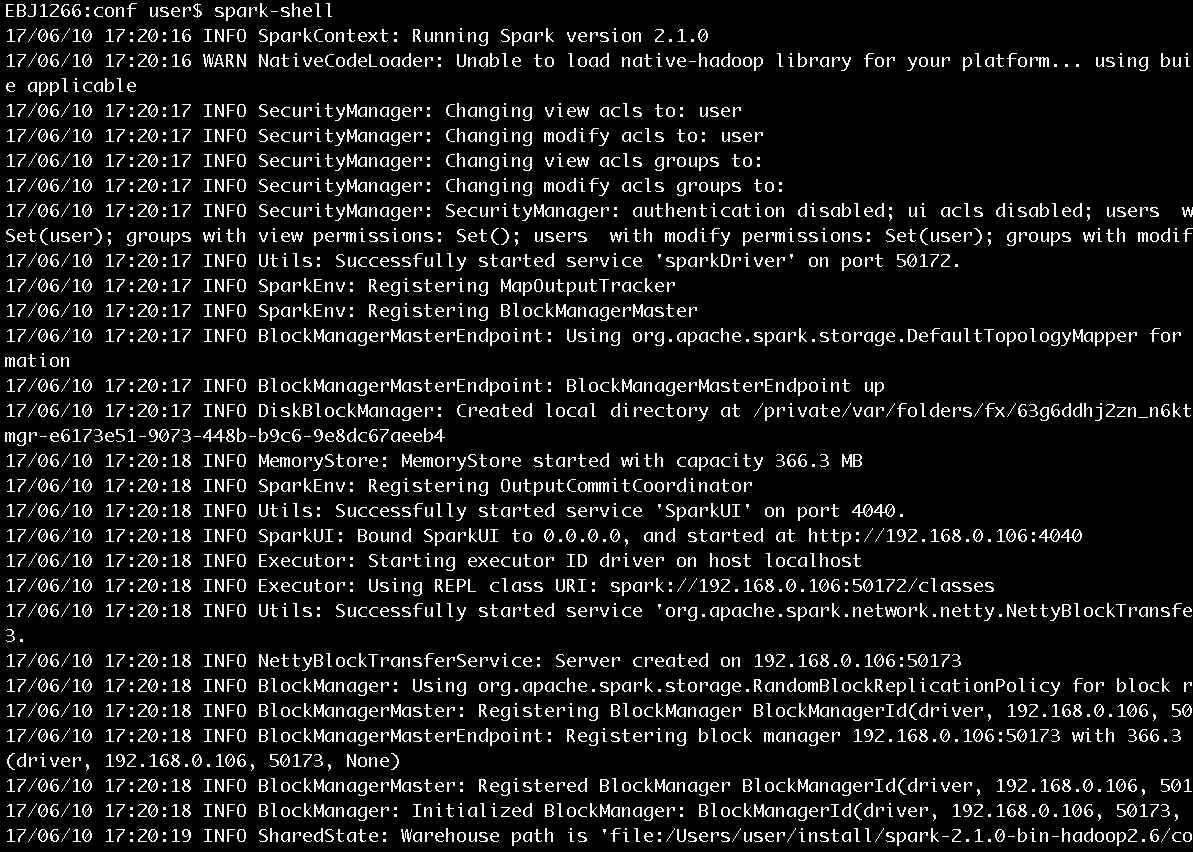
图5 Spark启动过程打印的部分信息
从图5展示的启动日志中我们可以看到SecurityManager、SparkEnv、BlockManagerMasterEndpoint、DiskBlockManager、MemoryStore、SparkUI、Executor、NettyBlockTransferService、BlockManager、BlockManagerMaster等信息。它们是做什么的?刚刚接触Spark的读者只需要知道这些信息即可,具体内容将在后边的博文给出。
执行word count
这一节,我们通过word count这个耳熟能详的例子来感受下Spark任务的执行过程。启动spark-shell后,会打开Scala命令行,然后按照以下步骤输入脚本:
步骤1
输入val lines =sc.textFile("../README.md", 2),以Spark安装目录下的README.md文件的内容作为word count例子的数据源,执行结果如图6所示。

图6 步骤1执行结果
图6告诉我们lines的实际类型是MapPartitionsRDD。
步骤2

图7 步骤2执行结果
图7告诉我们lines在经过flatMap方法的转换后得到的words的实际类型也是MapPartitionsRDD。
步骤3
对于得到的每个单词,通过输入val ones = words.map(w => (w,1)),将每个单词的计数初始化为1,执行结果如图8所示。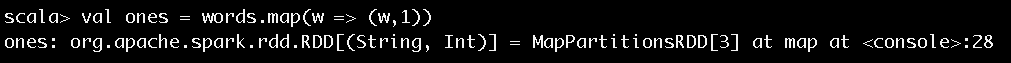
图8 步骤3执行结果
图8告诉我们words在经过map方法的转换后得到的ones的实际类型也是MapPartitionsRDD。
步骤4
输入val counts = ones.reduceByKey(_ + _),对单词进行计数值的聚合,执行结果如图9所示。

图9 步骤4执行结果
图9告诉我们ones在经过reduceByKey方法的转换后得到的counts的实际类型是ShuffledRDD。
步骤5
输入counts.foreach(println),将每个单词的计数值打印出来,作业的执行过程如图10和图11所示。作业的输出结果如图12所示。
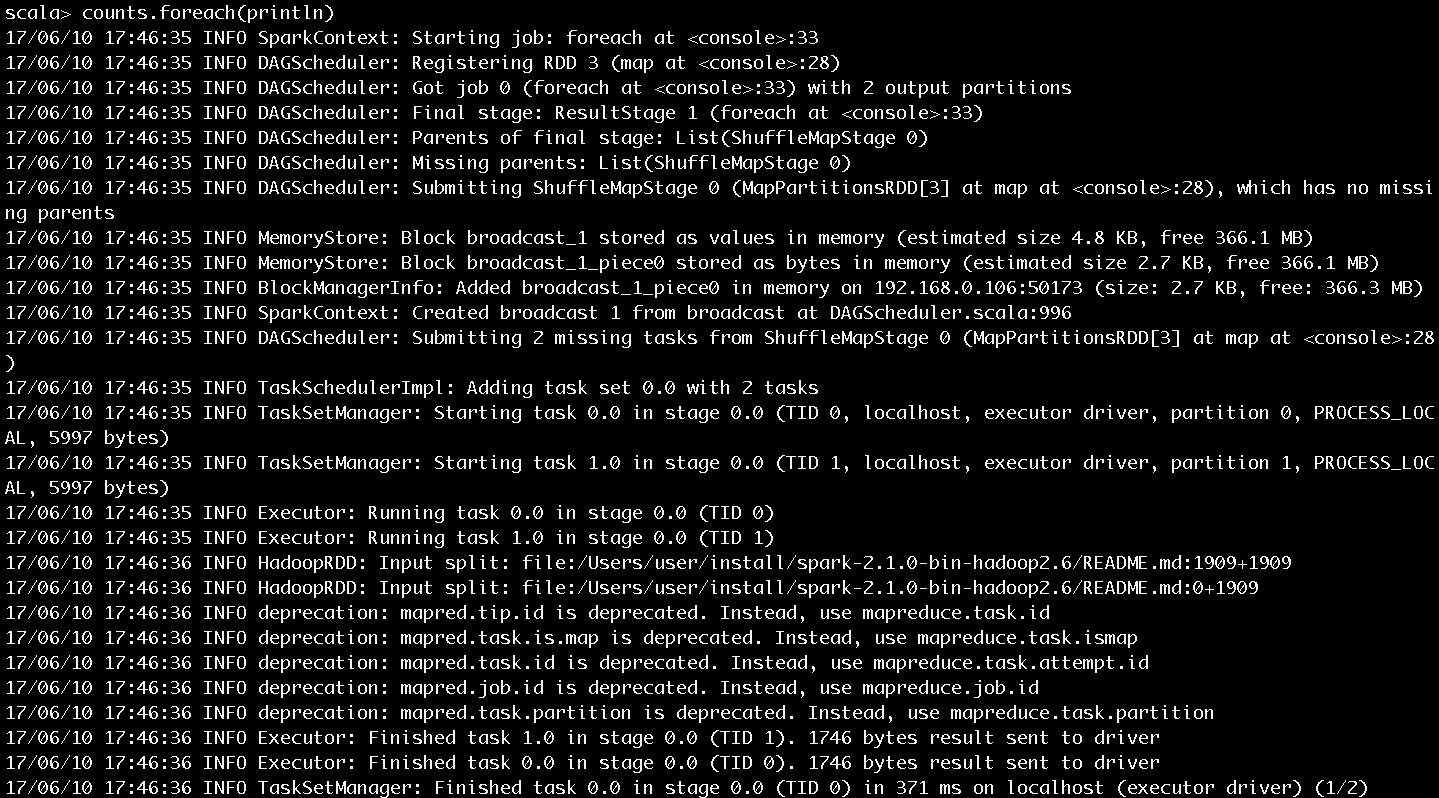
图10 步骤5执行过程第一部分
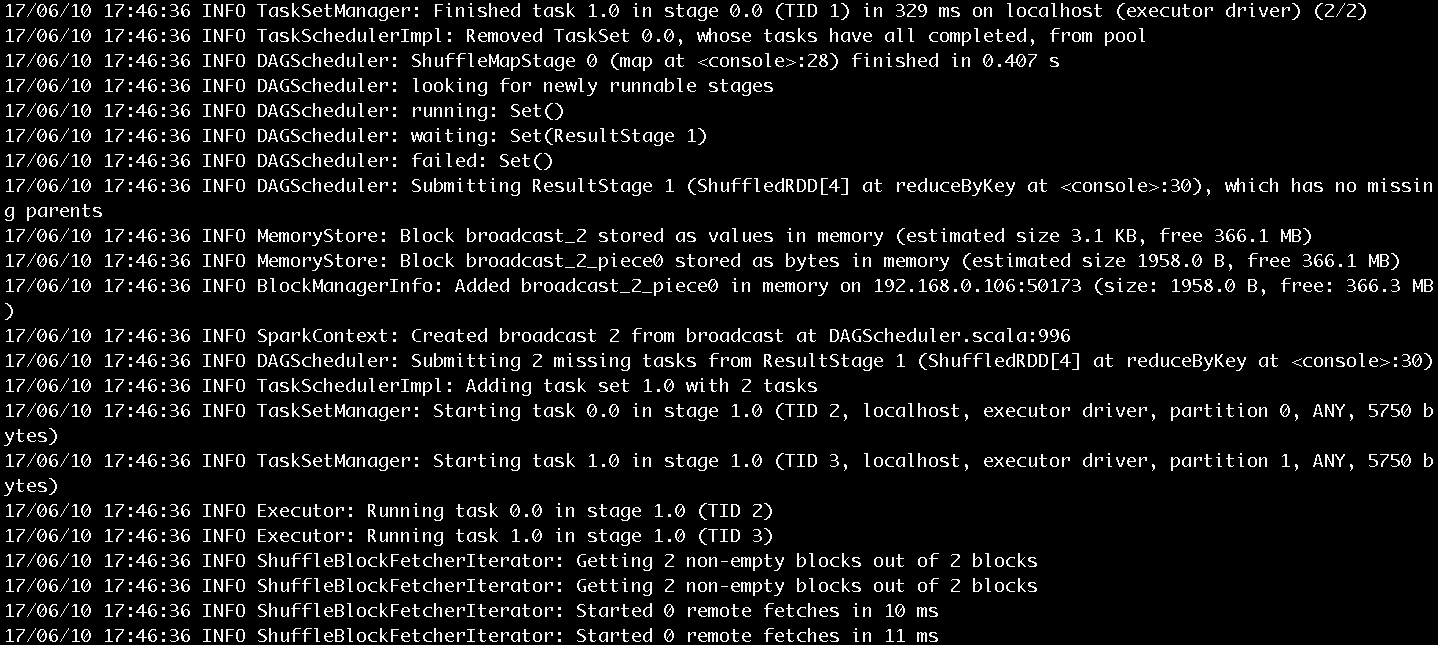
图11 步骤5执行过程第二部分
图10和图11展示了很多作业提交、执行的信息,这里挑选关键的内容进行介绍:
- SparkContext为提交的Job生成的ID是0。
- 一共有四个RDD,被划分为ResultStage和ShuffleMapStage。ShuffleMapStage的ID为0,尝试号为0。ResultStage的ID为1,尝试号也为0。在Spark中,如果Stage没有执行完成,就会进行多次重试。Stage无论是首次执行还是重试都被视为是一次Stage尝试(Stage Attempt),每次Attempt都有一个唯一的尝试号(AttemptNumber)。
- 由于Job有两个分区,所以ShuffleMapStage和ResultStage都有两个Task被提交。每个Task也会有多次尝试,因而也有属于Task的尝试号。从图中看出ShuffleMapStage中的两个Task和ResultStage中的两个Task的尝试号也都是0。
- HadoopRDD则用于读取文件内容。
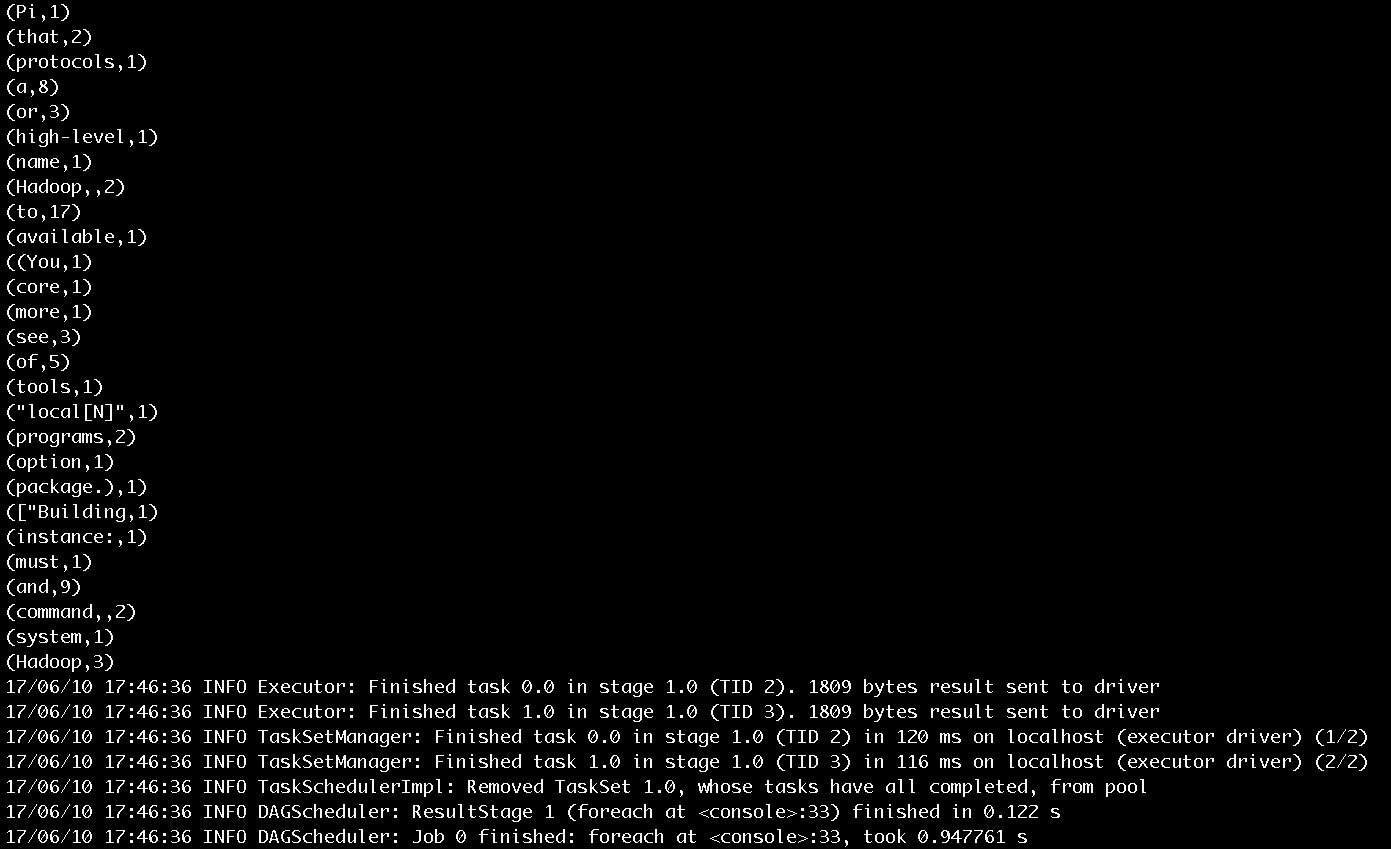
图12 步骤5输出结果
图12展示了单词计数的输出结果和最后打印的任务结束的日志信息。
本文介绍的word count例子是以SparkContext的API来实现的,读者朋友们也可以选择在spark-shell中通过运用SparkSession的API来实现。
有了对Spark的初次体验,下面可以来分析下spark-shell的实现原理了,请看——《Spark2.1.0——剖析spark-shell》
想要对Spark源码进行阅读的同学,可以看看《Spark2.1.0——代码结构及载入Ecplise方法》
关于《Spark内核设计的艺术 架构设计与实现》
经过近一年的准备,基于Spark2.1.0版本的《Spark内核设计的艺术 架构设计与实现》一书现已出版发行,图书如图: