最后更新时间:2017-07-13 11:10:49
原始文章链接:http://www.lovebxm.com/2017/07/13/mongodb_primer/
MongoDB - 简介
MongoDB 是一个基于分布式文件存储的数据库,由 C++ 语言编写,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
")
MongoDB - 安装及运行
- 下载
07/05/2017 Current Stable Release (3.4.6)
https://www.mongodb.com/download-center#community
- 创建数据目录
MongoDB 将数据目录存储在 db 目录下,需手动创建。
E:\MongoDB\data\db- 运行 MongoDB 服务器
为了从命令提示符下运行MongoDB服务器,你必须从MongoDB\bin目录中执行mongod.exe文件,不要关闭服务。ctrl + c关闭。
mongod.exe --dbpath E:\MongoDB\data\db- MongoDB 后台管理
运行 mongo.exe
MongoDB Shell是MongoDB自带的交互式Javascript shell,用来对MongoDB进行操作和管理的交互式环境。
- 将 MongoDB 服务器作为 Windows 服务运行
添加系统环境 path E:\MongoDB\Server\3.4\bin
检测:cmd 中输入 mongod --help
新建文件:E:\MongoDB\logs\logs.log
将 MongoDB 服务器作为 Windows 服务随 Windows 启动而开启:
mongod.exe --logpath "E:\MongoDB\logs\logs.log" --logappend --dbpath "E:\MongoDB\data" --directoryperdb --serviceName MongoDB --install开启 MongoDB 服务:net start MongoDB
停止 MongoDB 服务:net stop MongoDB
删除 MongoDB 服务:sc delete MongoDB
接下来就可以在 cmd 中运行 E:\MongoDB\Server\3.4\bin 里面的 *.exe 程序了
- shell 控制台
mongo - 数据库的还原
mongorestore 备份
mongodumpmongodb 启动的参数
")
mongoDB - 主要特点
- MongoDB安装简单。
- MongoDB的提供了一个面向文档存储,没有表结构的概念,每天记录可以有完全不同的结构,操作起来比较简单和容易。
- 完全的索引支持(单键索引、数组索引、全文索引、地理位置索引 等)
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB 支持多种编程语言:C C++ C# .NET Erlang Haskell Java JavaScript Lisp node.JS Perl PHP Python Ruby Scala 等
mongoDB - 工具
监控
- Munin:网络和系统监控工具
- Gangila:网络和系统监控工具
- Cacti:用于查看CPU负载, 网络带宽利用率,它也提供了一个应用于监控 MongoDB 的插件。
GUI
- Robomongo(Robo 3T)
- Fang of Mongo – 网页式,由Django和jQuery所构成。
- Futon4Mongo – 一个CouchDB Futon web的mongodb山寨版。
- Mongo3 – Ruby写成。
- MongoHub – 适用于OSX的应用程序。
- Opricot – 一个基于浏览器的MongoDB控制台, 由PHP撰写而成。
- Database Master — Windows的mongodb管理工具
- RockMongo — 最好的PHP语言的MongoDB管理工具,轻量级, 支持多国语言.
mongoDB - 三大重要概念
")
1. database 数据库
多个集合逻辑上组织在一起,就是数据库。
数据库命名规范:
- 不能是空字符串("")。
- 不得含有' '(空格)、.、$、/、\和\0 (空字符)。
- 应全部小写。
- 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
2. collection 集合
多个文档组成一个集合,相当于关系数据库的表。
所有存储在集合中的数据都是 BSON 格式,BSON 是类 JSON 的一种二进制形式的存储格式,简称 Binary JSON。
集合名命名规范:
- 集合名不能是空字符串""。
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
")
3. document 文档
MongoDB 将数据存储为一个文档,数据结构由键值对组成。
MongoDB 文档是一组键值对(即BSON,二进制的 JSON),类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
需要注意的是:
- 文档中的键值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
")
")
MongoDB - 数据类型
ObjectId:主键,一种特殊而且非常重要的类型,每个文档都会默认配置这个属性,属性名为_id,除非自己定义,方可覆盖
")
MongoDB - 常见操作
查看当前数据库
db查看所有数据库
没有数据的数据库不予显示
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
show dbs连接到指定的数据库
如果数据库不存在,则创建数据库,否则切换到指定数据库。
use db_name查看服务器状态
db.serverStatus()查看数据库统计信息
db.stats()删除数据库
db.dropDatabase()查看数据库中所有集合
show tables
或
show collections清空集合
删除里面的文档,但集合还在
db.col_name.remove({})删除集合
db.col_name.drop()查看集合详细信息
MongoDB 的3.0后的版本分了三种模式 queryPlanner、executionStats、allPlansExecution
db.col_name.find({key:value}).explain("allPlansExecution")MongoDB - 增删改查
插入
MongoDB 使用 insert() 或 save() 方法向集合中插入文档:
如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
insert() 或 save() 方法都可以向collection里插入数据,两者区别:
- 如果不指定 _id 字段,save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
- 使用save函数,如果原来的对象不存在,那他们都可以向collection里插入数据,如果已经存在,save会调用update更新里面的记录,而insert则会忽略操作
- insert可以一次性插入一个列表,而不用遍历,效率高, save则需要遍历列表,一个个插入。
db.col_name.insert(document)
db.col_name.save(document)插入一个文档到 col 集合中:
db.col_1.insert({
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})也可以将文档数据定义为一个变量,如下所示:
document = ({
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
});
db.col_2.insert(document)删除
remove() 函数是用来删除集合中的数据
在执行 remove() 函数前先执行 find() 命令来判断执行的条件是否正确,这是一个比较好的习惯。
db.col_name.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别。删除集合中所有文档
db.col.remove({})移除 col_1 集合中 title 为 MongoDB save 的文档,只删除第一条找到的记录
db.col_1.remove({'title':'MongoDB save'}, 1)更新
MongoDB 使用 update() 和 save() 方法来更新集合中的文档
update() 方法用于更新已存在的文档
db.col_name.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
- query : update 的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在 update 的记录,是否插入记录,true 为插入,默认是 false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。通过 update() 方法来更新 col_1 集合中的 title
$set 操作符为部分更新操作符,只更新 $set 之后的数据,而不是覆盖之前的数据
db.col_1.update({ 'title': 'MongoDB 教程' }, { $set: { 'title': 'MongoDB' } })以上语句只会修改第一条发现的文档,如果要修改多条相同的文档,则需要设置 multi 参数为 true。
db.col_1.update({ 'title': 'MongoDB 教程' }, { $set: { 'title': 'MongoDB' } }, { multi: true })save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.col_name.save(
<document>,
{
writeConcern: <document>
}
)以下实例中我们替换了 col_1 的文档数据:
document = ({
"_id": "1",
"title": "MongoDB save",
"description": "MongoDB 是一个 Nosql 数据库",
"by": "菜鸟",
"url": "http://www.runoob.com",
"tags": ["mongodb", "database", "NoSQL"],
});
db.col_1.save(document)查询
find() 方法,它返回集合中所有文档。
findOne() 方法,它只返回一个文档。
db.col_name.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。格式化输出:
db.col_name.find().pretty()查看集合中文档的个数:
db.col_name.find().count()跳过指定数量的数据:
db.col_name.find().skip()读取指定记录的条数:
db.col_name.find().limit()排序:
sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
db.col_name.find().sort({key:1})sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
Where 语句
如果你想获取"col"集合中 "likes" 大于100,小于 200 的数据,你可以使用以下命令:
db.col.find({likes : {$lt :200, $gt : 100}})
// 类似于SQL语句:
Select * from col where likes>100 AND likes<200;| 条件操作符 | 中文 | 全英文 |
|---|---|---|
| $gt | 大于 | greater than |
| $gte | 大于等于 | greater than equal |
| $lt | 小于 | less than |
| $lte | 小于等于 | less than equal |
| $ne | 不等于 | not equal |
")
$type 操作符
用来检索集合中匹配的数据类型
")
如果想获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令:
db.col.find({"title" : {$type : 2}})AND 条件
find() 方法可以传入多个键(key),每个键(key)以逗号隔开,语法格式如下:
db.col_name.find({key1:value1, key2:value2}).pretty()
// 类似于 SQL and 语句:
SELECT * FROM col_name WHERE key1='value1' AND key2=value2OR 条件
db.col_name.find({ $or: [{ "by": "菜鸟教程" }, { "title": "MongoDB 教程" }] }).pretty()
// 类似于 SQL or 语句:
SELECT * FROM col_name WHERE key1=value1 OR key2=value2AND 和 OR 联合使用
db.col_name.find({
"likes": {
$gt: 50
},
$or: [{
"by": "菜鸟教程"
}, {
"title": "MongoDB 教程"
}]
}).pretty()
// 类似常规 SQL 语句:
SELECT * FROM col_name where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')MongoDB - 索引
注意:从 mongoDB 3.0 开始,ensureIndex 被废弃,今后都仅仅是 createIndex 的一个别名。
索引通常能够极大的==提高查询的效率==,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
索引常用命令
getIndexes 查看集合索引情况
db.col_name.getIndexes()hint 强制使用索引
db.col_name.find({age:{$lt:30}}).hint({name:1, age:1}).explain()删除索引(不会删除 _id 索引)
db.col_name.dropIndexes()
db.col_name.dropIndex({firstname: 1})createIndex() 方法
MongoDB使用 createIndex() 方法来创建索引
key 为你要创建的索引字段,1为按升序创建索引,-1为按降序创建索引。
也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)
db.col_name.createIndex({key:1})createIndex() 接收可选参数,可选参数列表如下:
")
_id 索引
对于每个插入的数据,都会自动生成一条唯一的 _id 字段,_id 索引是绝大多数集合默认建立的索引
> db.col_1.insert({x:10})
WriteResult({ "nInserted" : 1 })
> db.col_1.find()
{ "_id" : ObjectId("59658e56aaf42d1c98dd95a2"), "x" : 10 }
> db.col_1.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "runoob.col_1"
}
]字段解释:
v 表示 version,在 Mongo3.2 之前的版本中,会存在 {v:0}(版本锁为0)的情况。在3.2之后的版本中,{v:0} 不再允许使用,这部分可以不去关注,因为 v 由系统自动管理
key 表示作为索引的键。1 或 -1表示排序模式,1为升序,1为降序
name 表示索引的名字,默认生成名称的规则是作为
索引的字段_排序模式ns 表示 namespace 命名空间,由
数据库名称.集合名称组成
单键索引
最普通的索引,不会自动创建
// 对 x 字段创建升序索引
> db.col_1.createIndex({x:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.col_1.find()
{ "_id" : ObjectId("59658e56aaf42d1c98dd95a2"), "x" : 10 }
> db.col_1.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "runoob.col_1"
},
{
"v" : 2,
"key" : {
"x" : 1
},
"name" : "x_1",
"ns" : "runoob.col_1"
}
]多键索引
单键索引的值为一个单一的值,多键索引的值有多个数据(如数组)
如果mongoDB中插入数组类型的多键数据,索引是自动建立的,无需刻意指定
> db.col_1.insert({z:[1,2,3,4,5]})
WriteResult({ "nInserted" : 1 })
> db.col_1.find()
{ "_id" : ObjectId("59658e56aaf42d1c98dd95a2"), "x" : 10 }
{ "_id" : ObjectId("5965923eaaf42d1c98dd95a3"), "y" : 20 }
{ "_id" : ObjectId("59659828aaf42d1c98dd95a4"), "z" : [ 1, 2, 3, 4, 5 ] }
> db.col_1.find({z:3})
{ "_id" : ObjectId("59659828aaf42d1c98dd95a4"), "z" : [ 1, 2, 3, 4, 5 ] }复合索引
同时对多个字段创建索引
> db.col_2.insert({x:10,y:20,z:30})
WriteResult({ "nInserted" : 1 })
> db.col_2.find()
{ "_id" : ObjectId("59659a57aaf42d1c98dd95a5"), "x" : 10, "y" : 20, "z" : 30 }
> db.col_2.createIndex({x:1,y:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.col_2.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "runoob.col_2"
},
{
"v" : 2,
"key" : {
"x" : 1,
"y" : 1
},
"name" : "x_1_y_1",
"ns" : "runoob.col_2"
}
]过期索引
又称 TTL(Time To Live,生存时间)索引,即在一段时间后会过期的索引(如登录信息、日志等)
过期后的索引会连同文档一起删除
expireAfterSeconds:指定一个以秒为单位的数值,设定集合的生存时间。
注意:
- 存储在过期索引字段的值必须是指定的时间类型(必须是 ISODate 或 ISODate 数组,不能使用时间戳,否则不能被自动删除)
- 如果指定了 ISODate 数组,则按照最小的时间进行删除
- 过期索引不能是复合索引(不能指定两个过期时间)
- 删除时间存在些许误差(1 分钟左右)
> db.col_3.insert({x:new Date()})
WriteResult({ "nInserted" : 1 })
> db.col_3.find()
{ "_id" : ObjectId("59659f3baaf42d1c98dd95a7"), "x" : ISODate("2017-07-12T04:02:03.835Z") }
> db.col_3.createIndex({x:1},{expireAfterSeconds:10})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.col_3.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "runoob.col_3"
},
{
"v" : 2,
"key" : {
"x" : 1
},
"name" : "x_1",
"ns" : "runoob.col_3",
"expireAfterSeconds" : 10
}
]
> db.col_3.find()
// 无返回全文索引
场景:全网站关键词搜索
key-value 中,key 此时为 $**(也可以是具体某 key),value 此时为一个固定的字符串(如 text)
全文索引相似度,与 sort 函数一起使用效果更好
db.col_7.find({ $text: { $search: "aa bb" } }, { score: { $meta: "textScore" } }).sort({ score: { $meta: "textScore" } })注意:
- 每个集合只能创建一个全文索引
- MongoDB 从 2.4 版本开始支持全文检索,从 3.2 版本开始支持中文
- (好像)只能对整个单词查询,不能对单词的截取部分查询
- 关键词之间的空格表示
或 - 关键词之前的 - 表示
非 - 关键词加引号表示
与(需用 \ 转义)
> db.col_7.find()
{ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
{ "_id" : ObjectId("5965aa8faaf42d1c98dd95b1"), "title" : "abc def", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.createIndex({"title": "text"})
> db.col_7.find({$text:{$search:"aa"}})
{ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.find({$text:{$search:"aa cc"}})
{ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.find({$text:{$search:"\"aa\" \"cc\""}})
{ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.find({$text:{$search:"aa bb"}},{score:{$meta:"textScore"}}).sort({score:{$meta:"textScore"}})
{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》", "score" : 1.5 }
{ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》", "score" : 1.3333333333333333 }
> db.col_7.dropIndexes()
> db.col_7.createIndex({"author": "text"}))
> db.col_7.find({$text:{$search:"小明"}})})
>
> db.col_7.find({$text:{$search:"白小明"}})
{ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
{ "_id" : ObjectId("5965aa8faaf42d1c98dd95b1"), "title" : "abc def", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }地理位置索引
查看最近的点
MongoDB - 聚合
==分组计算==
MongoDB 中聚合主要用于处理数据(如平均值,求和等),并返回计算后的数据结果。类似sql语句中的 count(*)。
aggregate() 方法
db.col_name.aggregate(AGGREGATE_OPERATION)下表展示了一些聚合的表达式:
")
实例
计算每个作者所写的文章数
在下面的例子中,我们通过字段by_user字段对数据进行分组,并计算by_user字段相同值的总和。
集合中的数据如下:
{
"_id" : ObjectId("5963b992a812aa05b9d2e765"),
"title" : "MongoDB Overview",
"description" : "MongoDB is no sql database",
"by_user" : "runoob.com",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
{
"_id" : ObjectId("5963b9aaa812aa05b9d2e766"),
"title" : "NoSQL Overview",
"description" : "No sql database is very fast",
"by_user" : "runoob.com",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 10
}
{
"_id" : ObjectId("5963b9bba812aa05b9d2e767"),
"title" : "Neo4j Overview",
"description" : "Neo4j is no sql database",
"by_user" : "Neo4j",
"url" : "http://www.neo4j.com",
"tags" : [
"neo4j",
"database",
"NoSQL"
],
"likes" : 750
}使用aggregate()计算结果如下:
db.col_1.aggregate([{
$group: {
_id: "$by_user",
num_tutorial: {
$sum: 1
}
}
}])
// 返回
{ "_id" : "Neo4j", "num_tutorial" : 1 }
{ "_id" : "runoob.com", "num_tutorial" : 2 }
// 以上实例类似sql语句
select by_user, count(*) from col_1 group by by_user聚合管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB 的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合管道常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
实例
$project 实例
0 为不显示,1为显示,默认情况下 _id 字段是 1
db.articles.aggregate({
$project: {
_id: 0,
title: 1,
by_user: 1,
}
});
// 返回
{ "title" : "MongoDB Overview", "by_user" : "runoob.com" }
{ "title" : "NoSQL Overview", "by_user" : "runoob.com" }
{ "title" : "Neo4j Overview", "by_user" : "Neo4j" }$match 实例
$match 用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
db.articles.aggregate([
{ $match: { score: { $gt: 70, $lte: 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
]);
// 返回
{ "_id" : null, "count" : 1 }$skip 实例
经过 $skip 管道操作符处理后,前2个文档被"过滤"掉。
db.col_1.aggregate({ $skip: 2 });MongoDB - 复制
MongoDB 复制(副本集)是==将数据同步在多个服务器==的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
特点:
- 保障数据的安全性
- 数据高可用性 (24*7)
- 灾难恢复,复制允许您从硬件故障和服务中断中恢复数据。
- 无需停机维护(如备份,重建索引,压缩)
分布式读取数据
N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
复制原理
mongodb 的复制至少需要两个节点。
- 其中一个是==主节点==,负责处理客户端请求,
- 其余的都是==从节点==,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
")
复制设置
- 关闭正在运行的MongoDB服务器。
现在我们通过指定 --replSet 选项来启动mongoDB
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"实例:
下面实例会启动一个名为rs0的MongoDB实例,其端口号为27017。
启动后打开命令提示框并连接上mongoDB服务。
在Mongo客户端使用命令rs.initiate()来启动一个新的副本集。
我们可以使用rs.conf()来查看副本集的配置
查看副本集状态使用 rs.status() 命令
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0副本集添加成员
添加副本集的成员,我们需要使用多条服务器来启动mongo服务。
进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
rs.add(HOST_NAME:PORT)实例:
假设你已经启动了一个名为 mongod1.net,端口号为27017的Mongo服务。
在客户端命令窗口使用rs.add() 命令将其添加到副本集中,命令如下所示:
rs.add("mongod1.net:27017")MongoDB 中你只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令
db.isMaster()MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
MongoDB - 分片
当MongoDB存储海量的数据时,==一台机器可能不足以存储数据==,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
为什么使用分片?
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
分片集群结构
")
三个主要组件:
- Shard: 用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
- Config Server: mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
- Query Routers: 前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
MongoDB - 监控
监控可以了解 MongoDB 的==运行情况==及==性能==
MongoDB中提供了 mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。
mongostat
它会间隔固定时间获取 mongodb 的当前运行状态,并输出。
如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用 mongostat 来查看 mongo 的状态。
mongostat")
mongotop
mongotop用来跟踪MongoDB的实例,提供每个集合的统计数据。默认情况下,mongotop每一秒刷新一次。
mongotop")
输出结果字段说明:
- ns:包含数据库命名空间,后者结合了数据库名称和集合。
- db:包含数据库的名称。名为 . 的数据库针对全局锁定,而非特定数据库。
- total:mongod花费的时间工作在这个命名空间提供总额。
- read:提供了大量的时间,这mongod花费在执行读操作,在此命名空间。
- write:提供这个命名空间进行写操作,这mongod花了大量的时间。
等待的时间长度,以秒为单位,默认 1s
mongotop 10报告每个数据库的锁的使用
mongotop --locksMongoDB - 备份与恢复
mongodump
在Mongodb中我们使用 mongodump 命令来备份MongoDB数据。
该命令可以导出所有数据到指定目录中。
mongodump命令可以通过参数指定导出的数据量级转存的服务器。
mongodump -h dbhost -d dbname -o dbdirectory
-h:MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:需要备份的数据库实例,例如:test
-o:备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。实例
备份 mongodb_study 数据库中的所有集合到 E:\MongoDB\dump
mongodump -h 127.0.0.1 -d mongodb_study -o E:\MongoDB\dump不带任何参数,即在当前目录下备份所有数据库实例
mongodump备份所有MongoDB数据
mongodump --host HOST_NAME --port PORT_NUMBER
// 如
mongodump --host w3cschool.cc --port 27017备份指定数据库的集合
mongodump --collection COLLECTION_NAME --db DB_NAME
// 如
mongodump --collection mycol --db testmongorestore
在Mongodb中我们使用 mongorestore 命令来恢复MongoDB数据。
mongorestore -h <hostname><:port> -d dbname <path>
--host <:port>, -h <:port>:MongoDB所在服务器地址,默认为: localhost:27017
--db , -d :需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
--drop:恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
<path>:mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。你不能同时指定 <path> 和 --dir 选项,--dir也可以设置备份目录。
--dir:指定备份的目录,你不能同时指定 <path> 和 --dir 选项。实例
恢复存放在 E:\MongoDB\dump 中的数据库 mongodb_study,恢复前后的数据库名不必相同
mongorestore -h localhost /db mongodb_study /dir E:\MongoDB\dump\mongodb_studyNode.js 连接 MongoDB
与 MySQL 不同的是 MongoDB 会自动创建数据库和集合,所以使用前我们不需要手动去创建。
安装驱动:npm install mongodb
运行 node:node connect
实例
connect.js
const MongoClient = require('mongodb').MongoClient;
// 自动创建数据库 runoob
let mongoConnect = 'mongodb://localhost:27017/runoob';
// 插入数据,插入到数据库 runoob 的 site 集合中
let insertData = function(db, callback) {
// 自动创建集合 site
let collection = db.collection('site');
// 插入文档
let data = [{
"name": "菜鸟教程",
"url": "www.runoob.com"
}, {
"name": "菜鸟工具",
"url": "c.runoob.com"
}];
collection.insert(data, function(err, result) {
if (err) {
console.log('Error:' + err);
return;
}
callback(result);
});
};
// 删除数据,删除所有 name 为 "菜鸟工具" 的文档
let deleteData = function(db, callback) {
let collection = db.collection('site');
let whereStr = {
"name": "菜鸟工具"
};
collection.remove(whereStr, function(err, result) {
if (err) {
console.log('Error:' + err);
return;
}
callback(result);
});
};
// 修改数据,将所以 name 为 "菜鸟教程" 的 url 改为 https://www.runoob.com
let updateData = function(db, callback) {
let collection = db.collection('site');
let whereStr = {
"name": "菜鸟教程"
};
let updateStr = {
$set: {
"url": "https://www.runoob.com"
}
};
collection.update(whereStr, updateStr, {
multi: true
}, function(err, result) {
if (err) {
console.log('Error:' + err);
return;
}
callback(result);
});
};
// 查询数据,查询 name 为 "菜鸟教程" 的数据
let selectData = function(db, callback) {
let collection = db.collection('site');
let whereStr = {
"name": '菜鸟教程'
};
collection.find(whereStr).toArray(function(err, result) {
if (err) {
console.log('Error:' + err);
return;
}
callback(result);
});
};
MongoClient.connect(mongoConnect, function(err, db) {
console.log("连接成功!");
insertData(db, function(result) {
console.log("插入数据成功!");
console.log(result);
db.close();
});
deleteData(db, function(result) {
console.log("删除数据成功!");
console.log(result);
db.close();
});
updateData(db, function(result) {
console.log("修改数据成功!");
console.log(result);
db.close();
});
selectData(db, function(result) {
console.log("查询数据成功!");
console.log(result);
db.close();
});
});mongoose
Mongoose学习参考文档——基础篇:https://cnodejs.org/topic/504b4924e2b84515770103dd
mongoose学习笔记:https://cnodejs.org/topic/58b911997872ea0864fee313
mongoose学习文档:http://www.cnblogs.com/y-yxh/p/5689555.html
Nodejs学习笔记(十四)— Mongoose介绍和入门:http://www.cnblogs.com/zhongweiv/p/mongoose.html
Mongoose全面理解:http://www.cnblogs.com/jayruan/p/5123754.html
Node.js 有针对 MongoDB 的数据库驱动:mongodb。你可以使用 npm install mongodb 来安装。不过直接使用 mongodb 模块虽然强大而灵活,但有些繁琐,我就使用 mongoose 吧。
Mongoose 基于nodejs、构建在 mongodb 之上,使用 javascript 编程,是==连接 mongodb 数据库的软件包==,使mongodb的文档数据模型变的优雅起来,方便对mongodb文档型数据库的连接和增删改查等常规数据操作。
mongoose 是当前使用 mean(mongodb express angularjs nodejs)全栈开发必用的连接数据库软件包。
==mongoose ,提供了Schema、Model 和 Document 对象,用起来更为方便。== 另外,mongoose 还有 Query 和 Aggregate 对象:Query 实现查询、Aggregate 实现聚合
mongoose 三个重要概念
")
Schema、Model、Entity 的关系:Schema生成Model,Model创造Entity,Model和Entity都可对数据库操作造成影响,但Model比Entity更具操作性。
1. Schema 模式
Schema 对象定义==文档结构==,可以定义字段、类型、唯一性、索引、验证等。
Schema 不仅定义了文档结构和使用性能,还可以有扩展插件、实例方法、静态方法、复合索引、文档生命周期钩子
// new mongoose.Schema() 中传入一个 JSON 对象,定义属性和属性类型
var BlogSchema = new mongoose.Schema({
title: String,
author: String
});有的时候,我们创造的 Schema 不仅要为后面的 Model 和 Entity 提供公共的属性,还要提供公共的方法。
2. Model 模型
Model 对象表示集合中的所有文档
由 Schema 发布生成的模型,具有抽象属性和行为的数据库操作对
3. Document 文档
Document 可等同于 Entity
由 Model 创建的实体,他的操作也会影响数据库
使用
- 定义一个 Schema 模式
- 将该 Schema 发布为 Model
- 用 Model 创建 Entity
- Entity 是具有具体的数据库操作 CRUD 的
mongoose 的 connection 对象定义了一些事件,比如 connected open close error 等,我们可以监听这些事件。
const mongoose = require('mongoose');
let db = mongoose.connect('mongodb://127.0.0.1:27017/test');
db.connection.on('error', console.error.bind(console, '数据库连接失败:'));
db.connection.once('open', function() {
console.log('数据库连接成功!');
// 定义一个 Schema 模式
// new Schema() 中传入一个 JSON 对象,定义属性和属性类型
let PersonSchema = new mongoose.Schema({
name: {
type: String,
unique: true
},
password: String
});
// 将该 Schema 发布为 Model
let PersonModel = mongoose.model('col_1', PersonSchema);
// 拿到了 Model 对象,就可以执行增删改查等操作了
// 如果要执行查询,需要依赖 Model,当然 Entity 也是可以做到的
PersonModel.find(function(err, result) {
// 查询到的所有person
});
// 用 Model 创建 Entity
let personEntity = new PersonModel({
name: 'Krouky',
password: '10086'
});
// Entity 是具有具体的数据库操作 CRUD 的
// 执行完成后,数据库就有该数据了
personEntity.save(function(err, result) {
if (err) {
console.log(err);
} else {
console.log(`${result} saved!`);
}
});
});---title: mongoDB 学习笔记纯干货(mongoose、增删改查、聚合、索引、连接、备份与恢复、监控等等)tags: [mongoDB, mongoose, Node.js]---
最后更新时间:2017-07-13 11:10:49
原始文章链接:http://www.lovebxm.com/2017/07/13/mongodb_primer/
# MongoDB - 简介
官网:https://www.mongodb.com/
MongoDB 是一个基于分布式文件存储的数据库,由 C++ 语言编写,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。

<!-- more -->
# MongoDB - 安装及运行
1. 下载
07/05/2017 Current Stable Release (3.4.6)
https://www.mongodb.com/download-center#community
2. 创建数据目录
MongoDB 将数据目录存储在 db 目录下,需手动创建。
```E:\MongoDB\data\db```
3. 运行 MongoDB 服务器
为了从命令提示符下运行MongoDB服务器,你必须从`MongoDB\bin`目录中执行`mongod.exe`文件,不要关闭服务。`ctrl + c`关闭。
```mongod.exe --dbpath E:\MongoDB\data\db```
4. MongoDB 后台管理
运行 mongo.exe
MongoDB Shell是MongoDB自带的交互式Javascript shell,用来对MongoDB进行操作和管理的交互式环境。
5. 将 MongoDB 服务器作为 Windows 服务运行
添加系统环境 path `E:\MongoDB\Server\3.4\bin`
检测:cmd 中输入 `mongod --help`
新建文件:`E:\MongoDB\logs\logs.log`
将 MongoDB 服务器作为 Windows 服务随 Windows 启动而开启:
```mongod.exe --logpath "E:\MongoDB\logs\logs.log" --logappend --dbpath "E:\MongoDB\data" --directoryperdb --serviceName MongoDB --install```
开启 MongoDB 服务:`net start MongoDB`
停止 MongoDB 服务:`net stop MongoDB`
删除 MongoDB 服务:`sc delete MongoDB`
接下来就可以在 cmd 中运行 `E:\MongoDB\Server\3.4\bin` 里面的 `*.exe` 程序了
- shell 控制台 `mongo`- 数据库的还原 `mongorestore`- 备份 `mongodump`
6. mongodb 启动的参数

# mongoDB - 主要特点
- MongoDB安装简单。- MongoDB的提供了一个面向文档存储,没有表结构的概念,每天记录可以有完全不同的结构,操作起来比较简单和容易。- 完全的索引支持(单键索引、数组索引、全文索引、地理位置索引 等)- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。- MongoDB 支持多种编程语言:C C++ C# .NET Erlang Haskell Java JavaScript Lisp node.JS Perl PHP Python Ruby Scala 等
# mongoDB - 工具
监控
- Munin:网络和系统监控工具- Gangila:网络和系统监控工具- Cacti:用于查看CPU负载, 网络带宽利用率,它也提供了一个应用于监控 MongoDB 的插件。
GUI
- Robomongo(Robo 3T)- Fang of Mongo – 网页式,由Django和jQuery所构成。- Futon4Mongo – 一个CouchDB Futon web的mongodb山寨版。- Mongo3 – Ruby写成。- MongoHub – 适用于OSX的应用程序。- Opricot – 一个基于浏览器的MongoDB控制台, 由PHP撰写而成。- Database Master — Windows的mongodb管理工具- RockMongo — 最好的PHP语言的MongoDB管理工具,轻量级, 支持多国语言.
# mongoDB - 三大重要概念

## 1. database 数据库
多个集合逻辑上组织在一起,就是数据库。
数据库命名规范:
- 不能是空字符串("")。- 不得含有' '(空格)、.、$、/、\和\0 (空字符)。- 应全部小写。- 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
## 2. collection 集合
多个文档组成一个集合,相当于关系数据库的表。
所有存储在集合中的数据都是 BSON 格式,BSON 是类 JSON 的一种二进制形式的存储格式,简称 Binary JSON。
集合名命名规范:
- 集合名不能是空字符串""。- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。- 集合名不能以"system."开头,这是为系统集合保留的前缀。- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。

## 3. document 文档
MongoDB 将数据存储为一个文档,数据结构由键值对组成。
MongoDB 文档是一组键值对(即BSON,二进制的 JSON),类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。- .和$有特别的意义,只有在特定环境下才能使用。- 以下划线"_"开头的键是保留的(不是严格要求的)。
需要注意的是:
- 文档中的键值对是有序的。- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。- MongoDB区分类型和大小写。- MongoDB的文档不能有重复的键。- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
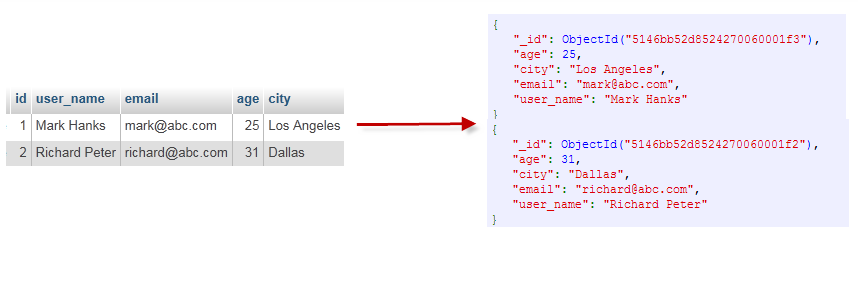
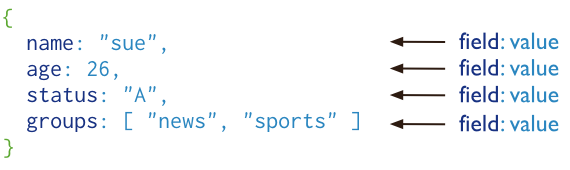
# MongoDB - 数据类型
ObjectId:主键,一种特殊而且非常重要的类型,每个文档都会默认配置这个属性,属性名为_id,除非自己定义,方可覆盖

# MongoDB - 常见操作
## 查看当前数据库
```db```
## 查看所有数据库
没有数据的数据库不予显示
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
```show dbs```
## 连接到指定的数据库
如果数据库不存在,则创建数据库,否则切换到指定数据库。
```use db_name```
## 查看服务器状态
```db.serverStatus()```
## 查看数据库统计信息
```db.stats()```
## 删除数据库
```db.dropDatabase()```
## 查看数据库中所有集合
```show tables或show collections```
## 清空集合
删除里面的文档,但集合还在
```db.col_name.remove({})```
删除集合
```db.col_name.drop()```
查看集合详细信息
MongoDB 的3.0后的版本分了三种模式 queryPlanner、executionStats、allPlansExecution
```db.col_name.find({key:value}).explain("allPlansExecution")```
# MongoDB - 增删改查
## 插入
MongoDB 使用 insert() 或 save() 方法向集合中插入文档:
如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
insert() 或 save() 方法都可以向collection里插入数据,两者区别:- 如果不指定 _id 字段,**save() 方法**类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。- 使用save函数,如果原来的对象不存在,那他们都可以向collection里插入数据,如果已经存在,save会调用update更新里面的记录,而insert则会忽略操作- insert可以一次性插入一个列表,而不用遍历,效率高, save则需要遍历列表,一个个插入。
```db.col_name.insert(document)
db.col_name.save(document)```
插入一个文档到 col 集合中:
```db.col_1.insert({ title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: '菜鸟教程', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100})```
也可以将文档数据定义为一个变量,如下所示:
```document = ({ title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: '菜鸟教程', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100});
db.col_2.insert(document)```
## 删除
remove() 函数是用来删除集合中的数据
在执行 remove() 函数前先执行 find() 命令来判断执行的条件是否正确,这是一个比较好的习惯。
```db.col_name.remove( <query>, { justOne: <boolean>, writeConcern: <document> })
- query :(可选)删除的文档的条件。- justOne : (可选)如果设为 true 或 1,则只删除一个文档。- writeConcern :(可选)抛出异常的级别。```
删除集合中所有文档
```db.col.remove({})```
移除 col_1 集合中 title 为 MongoDB save 的文档,只删除第一条找到的记录
```db.col_1.remove({'title':'MongoDB save'}, 1)```
## 更新
MongoDB 使用 update() 和 save() 方法来更新集合中的文档
**update() 方法**用于更新已存在的文档
```db.col_name.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document> })
- query : update 的查询条件,类似sql update查询内where后面的。- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的- upsert : 可选,这个参数的意思是,如果不存在 update 的记录,是否插入记录,true 为插入,默认是 false,不插入。- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。- writeConcern :可选,抛出异常的级别。```
通过 update() 方法来更新 col_1 集合中的 title
$set 操作符为部分更新操作符,只更新 $set 之后的数据,而不是覆盖之前的数据
```db.col_1.update({ 'title': 'MongoDB 教程' }, { $set: { 'title': 'MongoDB' } })```
以上语句只会修改第一条发现的文档,如果要修改多条相同的文档,则需要设置 multi 参数为 true。
```db.col_1.update({ 'title': 'MongoDB 教程' }, { $set: { 'title': 'MongoDB' } }, { multi: true })```
**save() 方法**通过传入的文档来替换已有文档。语法格式如下:
```db.col_name.save( <document>, { writeConcern: <document> })```
以下实例中我们替换了 col_1 的文档数据:
```document = ({ "_id": "1", "title": "MongoDB save", "description": "MongoDB 是一个 Nosql 数据库", "by": "菜鸟", "url": "http://www.runoob.com", "tags": ["mongodb", "database", "NoSQL"],});
db.col_1.save(document)```
## 查询
find() 方法,它返回集合中所有文档。
findOne() 方法,它只返回一个文档。
```db.col_name.find(query, projection)
- query :可选,使用查询操作符指定查询条件- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。```
格式化输出:
```db.col_name.find().pretty()```
查看集合中文档的个数:
```db.col_name.find().count()```
跳过指定数量的数据:
```db.col_name.find().skip()```
读取指定记录的条数:
```db.col_name.find().limit()```
排序:
sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
```db.col_name.find().sort({key:1})```
sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
### Where 语句
如果你想获取"col"集合中 "likes" 大于100,小于 200 的数据,你可以使用以下命令:
```db.col.find({likes : {$lt :200, $gt : 100}})
// 类似于SQL语句:Select * from col where likes>100 AND likes<200;```
条件操作符 | 中文 | 全英文---|---|---$gt | 大于 | greater than$gte | 大于等于 | greater than equal$lt | 小于 | less than$lte | 小于等于 | less than equal$ne | 不等于 | not equal

### $type 操作符
用来检索集合中匹配的数据类型

如果想获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令:
```db.col.find({"title" : {$type : 2}})```
### AND 条件
find() 方法可以传入多个键(key),每个键(key)以逗号隔开,语法格式如下:
```db.col_name.find({key1:value1, key2:value2}).pretty()
// 类似于 SQL and 语句:SELECT * FROM col_name WHERE key1='value1' AND key2=value2```
### OR 条件
```db.col_name.find({ $or: [{ "by": "菜鸟教程" }, { "title": "MongoDB 教程" }] }).pretty()
// 类似于 SQL or 语句:SELECT * FROM col_name WHERE key1=value1 OR key2=value2```
### AND 和 OR 联合使用
```db.col_name.find({ "likes": { $gt: 50 }, $or: [{ "by": "菜鸟教程" }, { "title": "MongoDB 教程" }]}).pretty()
// 类似常规 SQL 语句:SELECT * FROM col_name where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')```
# MongoDB - 索引
> [注意:从 mongoDB 3.0 开始,ensureIndex 被废弃,今后都仅仅是 createIndex 的一个别名。](http://docs.mongoing.com/manual-zh/reference/method/db.collection.ensureIndex.html)
索引通常能够极大的==提高查询的效率==,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
## 索引常用命令
getIndexes 查看集合索引情况
```db.col_name.getIndexes()```
hint 强制使用索引
```db.col_name.find({age:{$lt:30}}).hint({name:1, age:1}).explain()```
删除索引(不会删除 _id 索引)
```db.col_name.dropIndexes()
db.col_name.dropIndex({firstname: 1})```
## createIndex() 方法
MongoDB使用 createIndex() 方法来创建索引
key 为你要创建的索引字段,1为按升序创建索引,-1为按降序创建索引。
也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)
```db.col_name.createIndex({key:1})```
createIndex() 接收可选参数,可选参数列表如下:

### _id 索引
对于每个插入的数据,都会自动生成一条唯一的 _id 字段,_id 索引是绝大多数集合默认建立的索引
```> db.col_1.insert({x:10})WriteResult({ "nInserted" : 1 })
> db.col_1.find(){ "_id" : ObjectId("59658e56aaf42d1c98dd95a2"), "x" : 10 }
> db.col_1.getIndexes()[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "runoob.col_1" }]
```
字段解释:
- v 表示 version,在 Mongo3.2 之前的版本中,会存在 {v:0}(版本锁为0)的情况。在3.2之后的版本中,{v:0} 不再允许使用,这部分可以不去关注,因为 v 由系统自动管理
- key 表示作为索引的键。1 或 -1表示排序模式,1为升序,1为降序
- name 表示索引的名字,默认生成名称的规则是作为`索引的字段_排序模式`
- ns 表示 namespace 命名空间,由`数据库名称.集合名称`组成
### 单键索引
最普通的索引,不会自动创建
```// 对 x 字段创建升序索引
> db.col_1.createIndex({x:1}){ "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1}
> db.col_1.find(){ "_id" : ObjectId("59658e56aaf42d1c98dd95a2"), "x" : 10 }
> db.col_1.getIndexes()[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "runoob.col_1" }, { "v" : 2, "key" : { "x" : 1 }, "name" : "x_1", "ns" : "runoob.col_1" }]
```
### 多键索引
单键索引的值为一个单一的值,多键索引的值有多个数据(如数组)
如果mongoDB中插入数组类型的多键数据,索引是**自动建立**的,无需刻意指定
```> db.col_1.insert({z:[1,2,3,4,5]})WriteResult({ "nInserted" : 1 })
> db.col_1.find(){ "_id" : ObjectId("59658e56aaf42d1c98dd95a2"), "x" : 10 }{ "_id" : ObjectId("5965923eaaf42d1c98dd95a3"), "y" : 20 }{ "_id" : ObjectId("59659828aaf42d1c98dd95a4"), "z" : [ 1, 2, 3, 4, 5 ] }
> db.col_1.find({z:3}){ "_id" : ObjectId("59659828aaf42d1c98dd95a4"), "z" : [ 1, 2, 3, 4, 5 ] }```
### 复合索引
同时对多个字段创建索引
```> db.col_2.insert({x:10,y:20,z:30})WriteResult({ "nInserted" : 1 })
> db.col_2.find(){ "_id" : ObjectId("59659a57aaf42d1c98dd95a5"), "x" : 10, "y" : 20, "z" : 30 }
> db.col_2.createIndex({x:1,y:1}){ "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1}
> db.col_2.getIndexes()[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "runoob.col_2" }, { "v" : 2, "key" : { "x" : 1, "y" : 1 }, "name" : "x_1_y_1", "ns" : "runoob.col_2" }]```
### 过期索引
又称 TTL(Time To Live,生存时间)索引,即在一段时间后会过期的索引(如登录信息、日志等)
过期后的索引会连同文档一起删除
expireAfterSeconds:指定一个以秒为单位的数值,设定集合的生存时间。
注意:- 存储在过期索引字段的值必须是指定的时间类型(必须是 ISODate 或 ISODate 数组,不能使用时间戳,否则不能被自动删除)- 如果指定了 ISODate 数组,则按照最小的时间进行删除- 过期索引不能是复合索引(不能指定两个过期时间)- 删除时间存在些许误差(1 分钟左右)
```> db.col_3.insert({x:new Date()})WriteResult({ "nInserted" : 1 })
> db.col_3.find(){ "_id" : ObjectId("59659f3baaf42d1c98dd95a7"), "x" : ISODate("2017-07-12T04:02:03.835Z") }
> db.col_3.createIndex({x:1},{expireAfterSeconds:10}){ "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1}
> db.col_3.getIndexes()[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "runoob.col_3" }, { "v" : 2, "key" : { "x" : 1 }, "name" : "x_1", "ns" : "runoob.col_3", "expireAfterSeconds" : 10 }]
> db.col_3.find()// 无返回```
### 全文索引
场景:全网站关键词搜索
key-value 中,key 此时为 `$**`(也可以是具体某 key),value 此时为一个固定的字符串(如 `text`)
全文索引相似度,与 sort 函数一起使用效果更好
```db.col_7.find({ $text: { $search: "aa bb" } }, { score: { $meta: "textScore" } }).sort({ score: { $meta: "textScore" } })```
注意:- 每个集合只能创建一个全文索引- MongoDB 从 2.4 版本开始支持全文检索,从 3.2 版本开始支持中文- (好像)只能对整个单词查询,不能对单词的截取部分查询- 关键词之间的空格表示`或`- 关键词之前的 - 表示`非`- 关键词加引号表示`与` (需用 \ 转义)
```> db.col_7.find(){ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }{ "_id" : ObjectId("5965aa8faaf42d1c98dd95b1"), "title" : "abc def", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.createIndex({"title": "text"})
> db.col_7.find({$text:{$search:"aa"}}){ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.find({$text:{$search:"aa cc"}}){ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.find({$text:{$search:"\"aa\" \"cc\""}}){ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }
> db.col_7.find({$text:{$search:"aa bb"}},{score:{$meta:"textScore"}}).sort({score:{$meta:"textScore"}}){ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》", "score" : 1.5 }{ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》", "score" : 1.3333333333333333 }
> db.col_7.dropIndexes()
> db.col_7.createIndex({"author": "text"}))
> db.col_7.find({$text:{$search:"小明"}})})>
> db.col_7.find({$text:{$search:"白小明"}}){ "_id" : ObjectId("5965aa84aaf42d1c98dd95b0"), "title" : "aa bb cc", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }{ "_id" : ObjectId("5965aa8faaf42d1c98dd95b1"), "title" : "abc def", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }{ "_id" : ObjectId("5965aedfaaf42d1c98dd95b2"), "title" : "aa bb", "author" : "白小明", "article" : "这是白小明的一篇文章,标题《aa bb cc》" }```
### 地理位置索引
查看最近的点
# MongoDB - 聚合
==分组计算==
MongoDB 中聚合主要用于处理数据(如平均值,求和等),并返回计算后的数据结果。类似sql语句中的 count(*)。
## aggregate() 方法
```db.col_name.aggregate(AGGREGATE_OPERATION)```
下表展示了一些聚合的表达式:

### 实例
**计算每个作者所写的文章数**
在下面的例子中,我们通过字段by_user字段对数据进行分组,并计算by_user字段相同值的总和。
集合中的数据如下:
```{ "_id" : ObjectId("5963b992a812aa05b9d2e765"), "title" : "MongoDB Overview", "description" : "MongoDB is no sql database", "by_user" : "runoob.com", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100}{ "_id" : ObjectId("5963b9aaa812aa05b9d2e766"), "title" : "NoSQL Overview", "description" : "No sql database is very fast", "by_user" : "runoob.com", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 10}{ "_id" : ObjectId("5963b9bba812aa05b9d2e767"), "title" : "Neo4j Overview", "description" : "Neo4j is no sql database", "by_user" : "Neo4j", "url" : "http://www.neo4j.com", "tags" : [ "neo4j", "database", "NoSQL" ], "likes" : 750}```
使用aggregate()计算结果如下:
```db.col_1.aggregate([{ $group: { _id: "$by_user", num_tutorial: { $sum: 1 } }}])
// 返回{ "_id" : "Neo4j", "num_tutorial" : 1 }{ "_id" : "runoob.com", "num_tutorial" : 2 }
// 以上实例类似sql语句select by_user, count(*) from col_1 group by by_user```
## 聚合管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB 的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合管道常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。- $limit:用来限制MongoDB聚合管道返回的文档数。- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。- $group:将集合中的文档分组,可用于统计结果。- $sort:将输入文档排序后输出。- $geoNear:输出接近某一地理位置的有序文档。
### 实例
**$project 实例**
0 为不显示,1为显示,默认情况下 _id 字段是 1
```db.articles.aggregate({ $project: { _id: 0, title: 1, by_user: 1, }});
// 返回{ "title" : "MongoDB Overview", "by_user" : "runoob.com" }{ "title" : "NoSQL Overview", "by_user" : "runoob.com" }{ "title" : "Neo4j Overview", "by_user" : "Neo4j" }```
**$match 实例**
$match 用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
```db.articles.aggregate([ { $match: { score: { $gt: 70, $lte: 90 } } }, { $group: { _id: null, count: { $sum: 1 } } }]);
// 返回{ "_id" : null, "count" : 1 }```
**$skip 实例**
经过 $skip 管道操作符处理后,前2个文档被"过滤"掉。
```db.col_1.aggregate({ $skip: 2 });```
# MongoDB - 复制
MongoDB 复制(副本集)是==将数据同步在多个服务器==的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
特点:- 保障数据的安全性- 数据高可用性 (24*7)- 灾难恢复,复制允许您从硬件故障和服务中断中恢复数据。- 无需停机维护(如备份,重建索引,压缩)- 分布式读取数据
- N 个节点的集群- 任何节点可作为主节点- 所有写入操作都在主节点上- 自动故障转移- 自动恢复
## 复制原理
mongodb 的复制至少需要两个节点。- 其中一个是==主节点==,负责处理客户端请求,- 其余的都是==从节点==,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。

## 复制设置
1. 关闭正在运行的MongoDB服务器。
现在我们通过指定 --replSet 选项来启动mongoDB
```mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"```
实例:
下面实例会启动一个名为rs0的MongoDB实例,其端口号为27017。
启动后打开命令提示框并连接上mongoDB服务。
在Mongo客户端使用命令rs.initiate()来启动一个新的副本集。
我们可以使用rs.conf()来查看副本集的配置
查看副本集状态使用 rs.status() 命令
```mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0```
## 副本集添加成员
添加副本集的成员,我们需要使用多条服务器来启动mongo服务。
进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
```rs.add(HOST_NAME:PORT)```
实例:
假设你已经启动了一个名为 mongod1.net,端口号为27017的Mongo服务。
在客户端命令窗口使用rs.add() 命令将其添加到副本集中,命令如下所示:
```rs.add("mongod1.net:27017")```
MongoDB 中你只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令
```db.isMaster()```
MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
# MongoDB - 分片
当MongoDB存储海量的数据时,==一台机器可能不足以存储数据==,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
为什么使用分片?- 复制所有的写入操作到主节点- 延迟的敏感数据会在主节点查询- 单个副本集限制在12个节点- 当请求量巨大时会出现内存不足。- 本地磁盘不足- 垂直扩展价格昂贵
## 分片集群结构
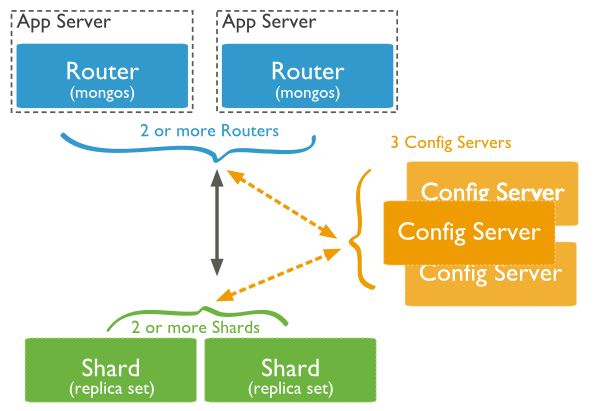
三个主要组件:- Shard: 用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障- Config Server: mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。- Query Routers: 前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
# MongoDB - 监控
监控可以了解 MongoDB 的==运行情况==及==性能==
MongoDB中提供了 mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。
## mongostat
它会间隔固定时间获取 mongodb 的当前运行状态,并输出。
如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用 mongostat 来查看 mongo 的状态。
```mongostat```

## mongotop
mongotop用来跟踪MongoDB的实例,提供每个集合的统计数据。默认情况下,mongotop每一秒刷新一次。
```mongotop```

输出结果字段说明:- ns:包含数据库命名空间,后者结合了数据库名称和集合。- db:包含数据库的名称。名为 . 的数据库针对全局锁定,而非特定数据库。- total:mongod花费的时间工作在这个命名空间提供总额。- read:提供了大量的时间,这mongod花费在执行读操作,在此命名空间。- write:提供这个命名空间进行写操作,这mongod花了大量的时间。
等待的时间长度,以秒为单位,默认 1s
```mongotop 10```
报告每个数据库的**锁**的使用
```mongotop --locks```
# MongoDB - 备份与恢复
## mongodump
在Mongodb中我们使用 `mongodump` 命令来备份MongoDB数据。
该命令可以导出所有数据到指定目录中。
mongodump命令可以通过参数指定导出的数据量级转存的服务器。
```mongodump -h dbhost -d dbname -o dbdirectory
-h:MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017-d:需要备份的数据库实例,例如:test-o:备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。```
### 实例
备份 mongodb_study 数据库中的所有集合到 E:\MongoDB\dump
```mongodump -h 127.0.0.1 -d mongodb_study -o E:\MongoDB\dump```
不带任何参数,即在当前目录下备份所有数据库实例
```mongodump```
备份所有MongoDB数据
```mongodump --host HOST_NAME --port PORT_NUMBER
// 如mongodump --host w3cschool.cc --port 27017```
备份指定数据库的集合
```mongodump --collection COLLECTION_NAME --db DB_NAME
// 如mongodump --collection mycol --db test```
## mongorestore
在Mongodb中我们使用 `mongorestore` 命令来恢复MongoDB数据。
```mongorestore -h <hostname><:port> -d dbname <path>
--host <:port>, -h <:port>:MongoDB所在服务器地址,默认为: localhost:27017--db , -d :需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2--drop:恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!<path>:mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。你不能同时指定 <path> 和 --dir 选项,--dir也可以设置备份目录。--dir:指定备份的目录,你不能同时指定 <path> 和 --dir 选项。```
### 实例
恢复存放在 E:\MongoDB\dump 中的数据库 mongodb_study,恢复前后的数据库名不必相同
```mongorestore -h localhost /db mongodb_study /dir E:\MongoDB\dump\mongodb_study```
# Node.js 连接 MongoDB
与 MySQL 不同的是 MongoDB 会自动创建数据库和集合,所以使用前我们不需要手动去创建。
安装驱动:`npm install mongodb`
运行 node:`node connect`
## 实例
connect.js
```jsconst MongoClient = require('mongodb').MongoClient;
// 自动创建数据库 runooblet mongoConnect = 'mongodb://localhost:27017/runoob';
// 插入数据,插入到数据库 runoob 的 site 集合中let insertData = function(db, callback) { // 自动创建集合 site let collection = db.collection('site'); // 插入文档 let data = [{ "name": "菜鸟教程", "url": "www.runoob.com" }, { "name": "菜鸟工具", "url": "c.runoob.com" }];
collection.insert(data, function(err, result) { if (err) { console.log('Error:' + err); return; } callback(result); });};
// 删除数据,删除所有 name 为 "菜鸟工具" 的文档let deleteData = function(db, callback) { let collection = db.collection('site'); let whereStr = { "name": "菜鸟工具" };
collection.remove(whereStr, function(err, result) { if (err) { console.log('Error:' + err); return; } callback(result); });};
// 修改数据,将所以 name 为 "菜鸟教程" 的 url 改为 https://www.runoob.comlet updateData = function(db, callback) { let collection = db.collection('site'); let whereStr = { "name": "菜鸟教程" }; let updateStr = { $set: { "url": "https://www.runoob.com" } };
collection.update(whereStr, updateStr, { multi: true }, function(err, result) { if (err) { console.log('Error:' + err); return; } callback(result); });};
// 查询数据,查询 name 为 "菜鸟教程" 的数据let selectData = function(db, callback) { let collection = db.collection('site'); let whereStr = { "name": '菜鸟教程' };
collection.find(whereStr).toArray(function(err, result) { if (err) { console.log('Error:' + err); return; } callback(result); });};
MongoClient.connect(mongoConnect, function(err, db) { console.log("连接成功!");
insertData(db, function(result) { console.log("插入数据成功!"); console.log(result); db.close(); });
deleteData(db, function(result) { console.log("删除数据成功!"); console.log(result); db.close(); });
updateData(db, function(result) { console.log("修改数据成功!"); console.log(result); db.close(); });
selectData(db, function(result) { console.log("查询数据成功!"); console.log(result); db.close(); });});
```
# mongoose
> Mongoose学习参考文档——基础篇:https://cnodejs.org/topic/504b4924e2b84515770103dd
> mongoose学习笔记:https://cnodejs.org/topic/58b911997872ea0864fee313
> mongoose学习文档:http://www.cnblogs.com/y-yxh/p/5689555.html
> Nodejs学习笔记(十四)— Mongoose介绍和入门:http://www.cnblogs.com/zhongweiv/p/mongoose.html
> Mongoose全面理解:http://www.cnblogs.com/jayruan/p/5123754.html
Node.js 有针对 MongoDB 的数据库驱动:mongodb。你可以使用 `npm install mongodb` 来安装。不过直接使用 mongodb 模块虽然强大而灵活,但有些繁琐,我就使用 mongoose 吧。
Mongoose 基于nodejs、构建在 mongodb 之上,使用 javascript 编程,是==连接 mongodb 数据库的软件包==,使mongodb的文档数据模型变的优雅起来,方便对mongodb文档型数据库的连接和增删改查等常规数据操作。
mongoose 是当前使用 mean(mongodb express angularjs nodejs)全栈开发必用的连接数据库软件包。
==mongoose ,提供了Schema、Model 和 Document 对象,用起来更为方便。== 另外,mongoose 还有 Query 和 Aggregate 对象:Query 实现查询、Aggregate 实现聚合
## mongoose 三个重要概念

Schema、Model、Entity 的关系:Schema生成Model,Model创造Entity,Model和Entity都可对数据库操作造成影响,但Model比Entity更具操作性。
### 1. Schema 模式
Schema 对象定义==文档结构==,可以定义字段、类型、唯一性、索引、验证等。
Schema 不仅定义了文档结构和使用性能,还可以有扩展插件、实例方法、静态方法、复合索引、文档生命周期钩子
```// new mongoose.Schema() 中传入一个 JSON 对象,定义属性和属性类型var BlogSchema = new mongoose.Schema({ title: String, author: String});
```
有的时候,我们创造的 Schema 不仅要为后面的 Model 和 Entity 提供公共的属性,还要提供公共的方法。
### 2. Model 模型
Model 对象表示集合中的所有文档
由 Schema 发布生成的模型,具有抽象属性和行为的数据库操作对
### 3. Document 文档
Document 可等同于 Entity
由 Model 创建的实体,他的操作也会影响数据库
## 使用
1. 定义一个 Schema 模式2. 将该 Schema 发布为 Model3. 用 Model 创建 Entity4. Entity 是具有具体的数据库操作 CRUD 的
mongoose 的 connection 对象定义了一些事件,比如 connected open close error 等,我们可以监听这些事件。
```const mongoose = require('mongoose');
let db = mongoose.connect('mongodb://127.0.0.1:27017/test');
db.connection.on('error', console.error.bind(console, '数据库连接失败:'));
db.connection.once('open', function() { console.log('数据库连接成功!');
// 定义一个 Schema 模式 // new Schema() 中传入一个 JSON 对象,定义属性和属性类型 let PersonSchema = new mongoose.Schema({ name: { type: String, unique: true }, password: String });
// 将该 Schema 发布为 Model let PersonModel = mongoose.model('col_1', PersonSchema);
// 拿到了 Model 对象,就可以执行增删改查等操作了 // 如果要执行查询,需要依赖 Model,当然 Entity 也是可以做到的 PersonModel.find(function(err, result) { // 查询到的所有person });
// 用 Model 创建 Entity let personEntity = new PersonModel({ name: 'Krouky', password: '10086' });
// Entity 是具有具体的数据库操作 CRUD 的 // 执行完成后,数据库就有该数据了 personEntity.save(function(err, result) { if (err) { console.log(err); } else { console.log(`${result} saved!`); } });});
```