查看Spark任务的详细信息时间:2022-10-31 17:08:38### 欢迎访问我的GitHub > 这里分类和汇总了欣宸的全部原创(含配套源码):[https://github.com/zq2599/blog_demos](https://github.com/zq2599/blog_demos) - 在学习Spark的过程中,查看任务的DAG、stage、task等详细信息是学习的重要手段,在此做个小结; ### 环境信息 - 本文对应的环境信息如下: 1. CentOS Linux release 7.5.1804 2. JDK:1.8.0_191 3. hadoop:2.7.7 4. spark:2.3.2 ### 参考文档(准备环境用到) - 搭建hadoop、spark、运行耗时任务,请参考以下文章: 1. 部署hadoop:[《Linux部署hadoop2.7.7集群》](https://blog.csdn.net/boling_cavalry/article/details/86774385); 2. on Yarn模式部署Spark集群:[《部署Spark2.2集群(on Yarn模式)》](https://blog.csdn.net/boling_cavalry/article/details/86795338); 3. 开发一个比较耗时的计算任务:[《spark实战之:分析*网站统计数据(java版)》](https://blog.csdn.net/boling_cavalry/article/details/87241814); - 经过以上准备,我们就有了一个可以用的Spark集群环境,并且计算任务也准备好了。 ### 观察运行时任务信息 - 例如通过执行以下命令启动了一个spark任务: ```shell ~/spark-2.3.2-bin-hadoop2.7/bin/spark-submit \ --class com.bolingcavalry.sparkdemo.app.WikiRank \ --executor-memory 2g \ --total-executor-cores 4 \ /home/hadoop/jars/sparkdemo-1.0-SNAPSHOT.jar \ 192.168.121.150 \ 8020 ``` - 此时控制台会有以下提示: ```shell 2019-10-07 11:03:54 INFO SparkUI:54 - Bound SparkUI to 0.0.0.0, and started at http://node0:4040 ``` - 此时用浏览器访问master机器的4040端口,可见信息如下图所示,事件、DAG、stage都有: 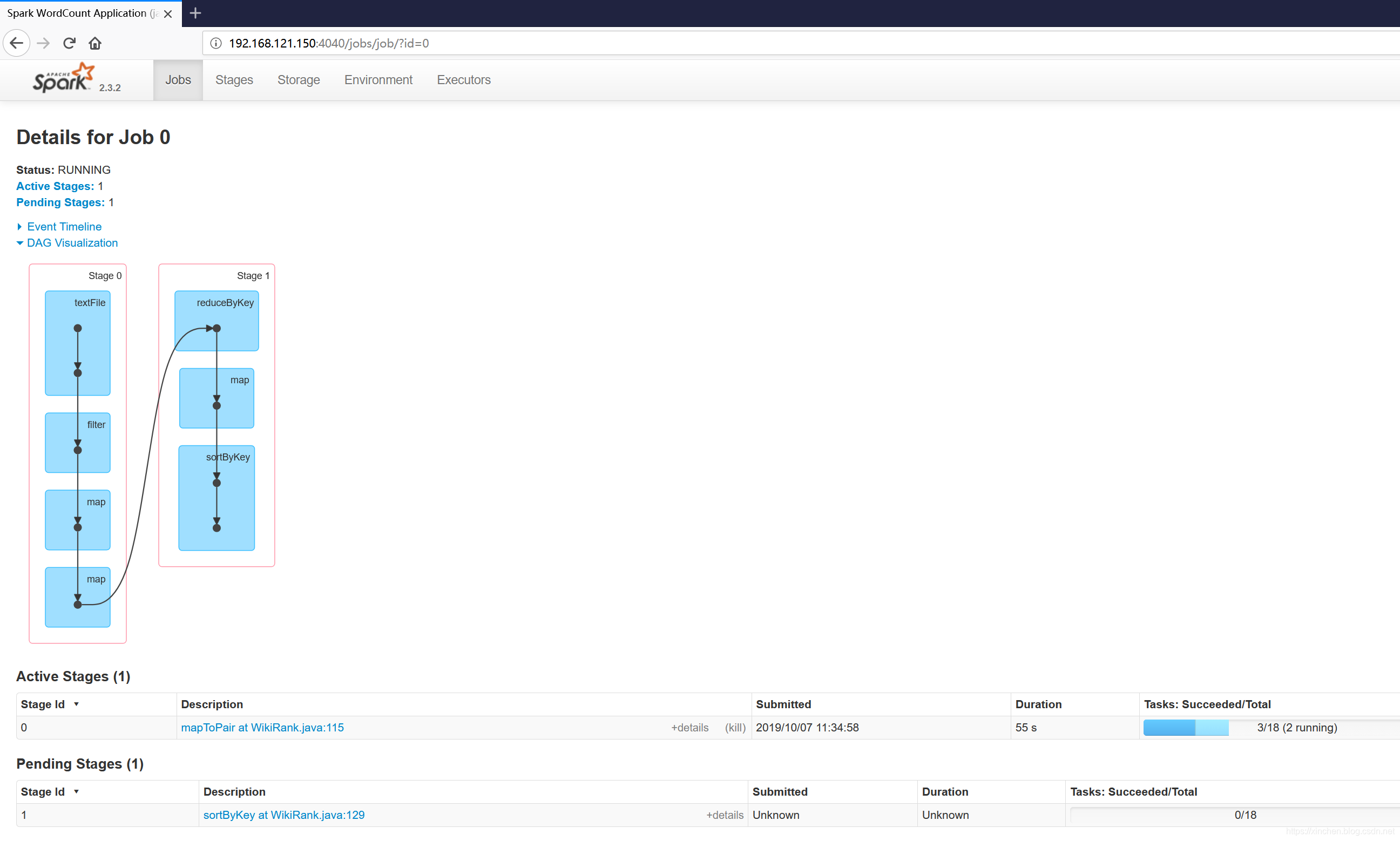 - 点击上图中stage的"Description",即可见到该stage下的所有task信息: 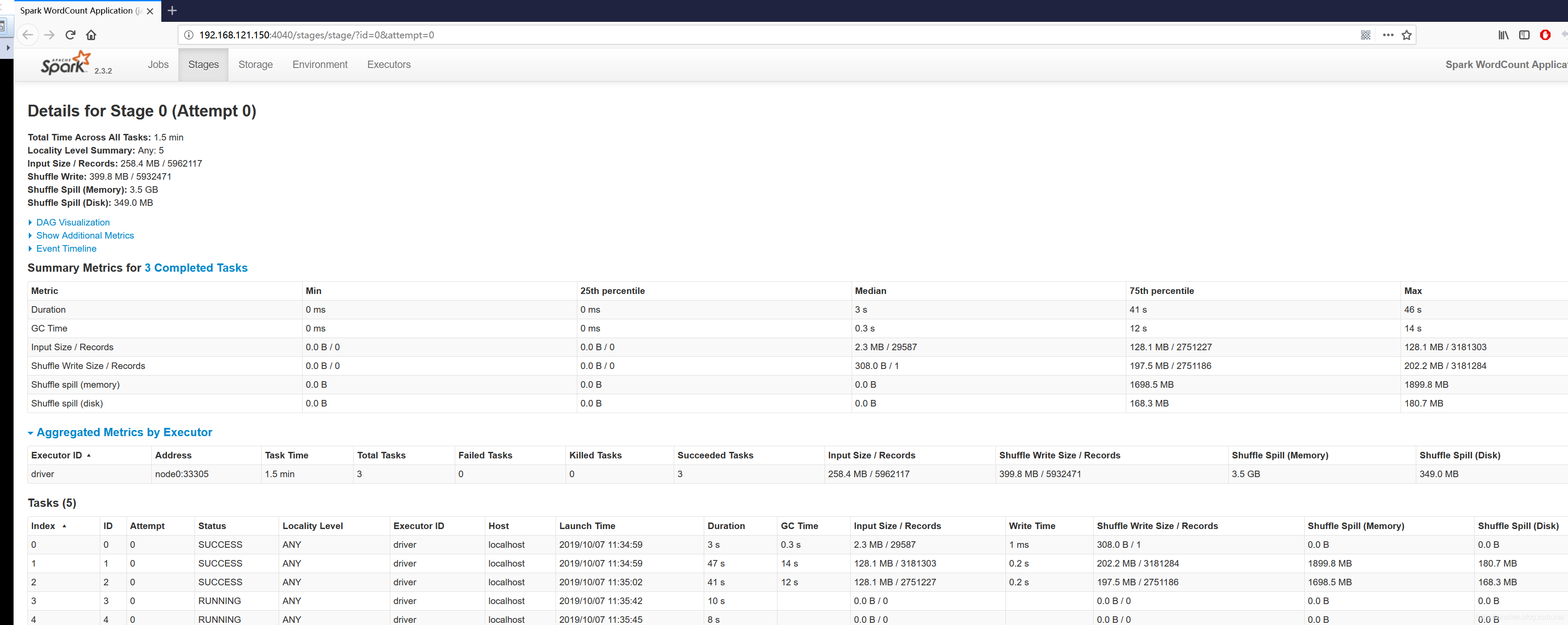 - job运行完成后,控制台有以下信息输出,此时再访问4040端口的webUI服务,发现已经不可访问了: ```shell 2019-10-07 11:45:29 INFO SparkUI:54 - Stopped Spark web UI at http://node0:4040 ``` ### 观察历史任务 - job结束后,4040端口提供的webUI服务也停止了,想回看已结束的任务信息需要配置和启动历史任务信息服务: - 打开配置文件 **spark-2.3.2-bin-hadoop2.7/conf/spark-defaults.conf** ,增加以下三个配置: ```configuration spark.eventLog.enabled true spark.eventLog.dir hdfs://node0:8020/var/log/spark spark.eventLog.compress true ``` - 上述配置中, **hdfs://node0:8020** 是hdfs的服务地址。 - 打开配置文件 **spark-env.sh** ,增加以下一个配置: ```shell export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node0:8020/var/log/spark" ``` - 上述配置中, **hdfs://node0:8020** 是hdfs的服务地址。 - 在hdfs的namenode执行以下命令,提前创建好日志文件夹: ```shell ~/hadoop-2.7.7/bin/hdfs dfs -mkdir -p /var/log/spark ``` - 启动历史任务服务: ```shell ~/spark-2.3.2-bin-hadoop2.7/sbin/start-history-server.sh ``` - 此后执行的spark任务信息都会保存下来,访问master机器的18080端口,即可见到所有历史任务的信息,点击查看详情,和前面的运行时任务的内容是一样的: 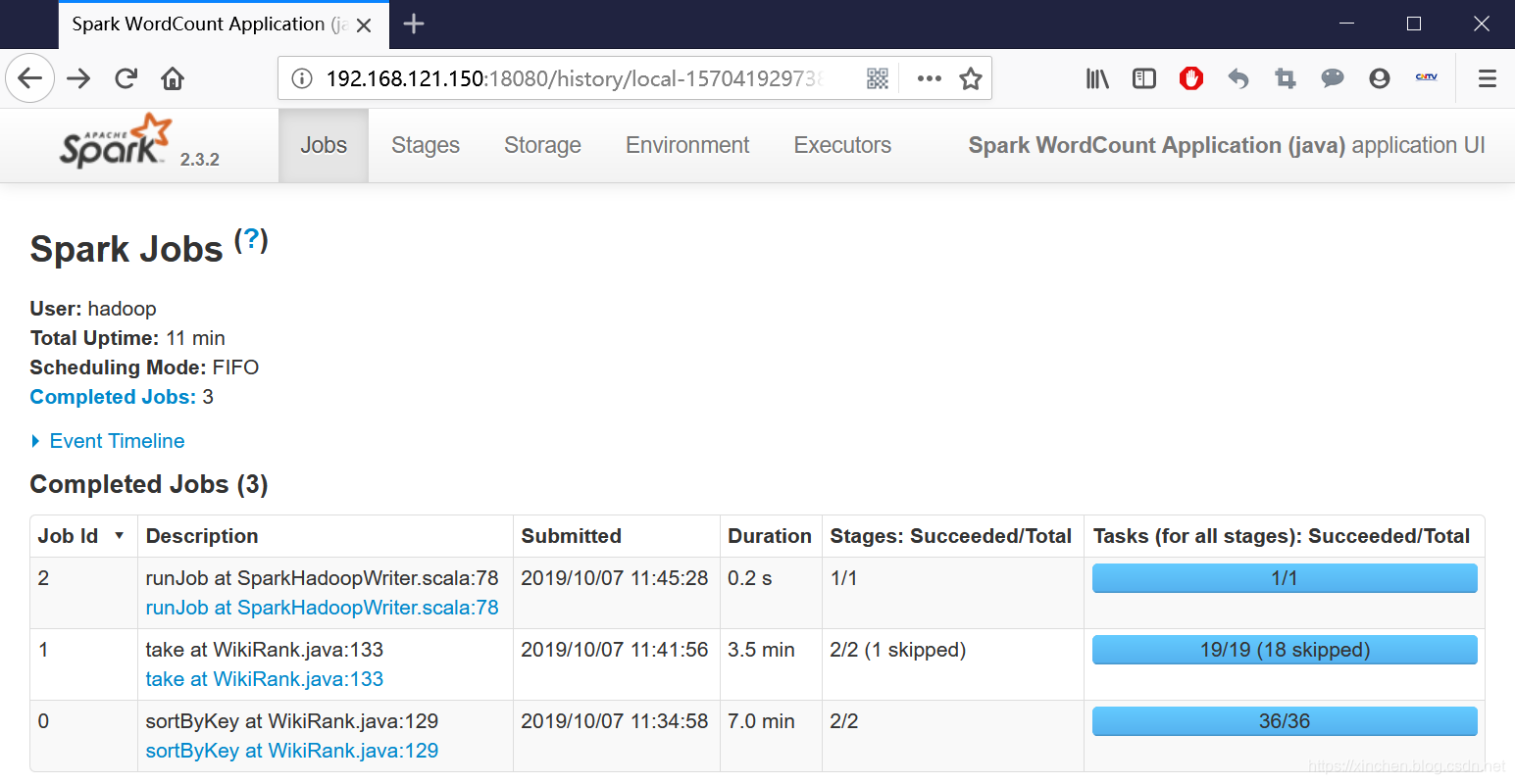 - 至此,运行时和历史任务的job详情都可以观察到了,可以帮助我们更好的学习和研究spark。 ### 欢迎关注ITpub:程序员欣宸 > [学习路上,你不孤单,欣宸原创一路相伴...](http://blog.itpub.net/70017844/)