Sqlserver存储引擎体系结构简介_Part1时间:2022-10-25 18:05:58官方文档https://learn.microsoft.com/zh-cn/sql/relational-databases/sql-server-guides?view=sql-server-2017 1、内存结构 SQL SERVER 内存空间主要可分为: 编译内存、缓冲池Buffer Pool、查询执行内存授予、锁管理器内存、 CLR1 内存 缓冲区管理组件由下列两种机制组成:用于访问及更新数据库页的缓冲区管理器和用于减少数据库文件 I/O 的缓冲区高速缓存(又称为“缓冲池”) 缓冲区管理器主要与下列组件交互: 资源管理器。此交互用于控制内存的整体使用情况以及 32 位平台中的地址空间使用情况。 数据库管理器和 SQL Server 操作系统 (SQLOS)。此交互用于低级文件 I/O 操作。 日志管理器。此交互用于预写日志记录。 2、物理结构 系统数据库启动顺序master-->model-->tempdb--msdb msdb依赖tempdb,tempdb依赖model,model依赖master 因为数据库每次重启都会重建tempdb,tempdb是使用model作为模板来创建的,如果model无法启动,则启动tempdb也会报错Could not create tempdb. You may not have enough disk space available. Free additional disk space by deleting other files on the tempdb drive and then restart SQL Server. Check for additional errors in the event log that may indicate why the tempdb files could not be initialized. tempdb无法启动的话,数据库实例无法启动 tempdb数据库的数据文件和日志文件被删除后,重启后会自动创建tempdb的数据文件和日志文件 msdb无法启动的话,数据库实例正常启动,服务方面sqlserver service和sqlserver agent service都正常启动,只是msdb数据库状态为Recovery Pending并且在SSMS中SQL Server Agent显示Agent XPs disabled。 master:记录SQL Server实例的所有系统级信息。 msdb:用于 SQL Server 代理计划警报和作业。 model:用作 SQL Server实例上创建的所有数据库的模板。 对 model 数据库进行的修改(如数据库大小、排序规则、恢复模式和其他数据库选项)将应用于以后创建的所有数据库。 tempdb :用于保存临时对象或中间结果集。 3、数据完整性校验 CHECKSUM: Checksum protection 校验和保护 SQL Server 2005 (9.x) 中引入的“校验和保护”提供了更强大的数据完整性检查。 此方法将对写入每一页中的数据进行校验和计算并将其值存储在页头中。 每次从磁盘读取存储了校验和的页时,数据库引擎将重新计算页中数据的校验和。如果新的校验和不同于已存储的校验和,则引发错误 824。 校验和保护比残缺页保护能捕获到更多的错误,因为它受到页中每个字节的影响,但它对资源的消耗较多。启用校验和后,当缓冲区管理器从磁盘读取页时均可以检测到因电源故障以及硬件或固件故障导致的错误。 TORN_PAGE_DETECTION: Torn page protection 残缺页保护 SQL Server 2000 (8.x) 中引入的撕裂页面保护主要是由于电源故障而检测页面损坏的方法。 例如,意外电源故障可能导致只有部分页写入磁盘。 使用残缺页保护时,在将8KB的数据库页写入磁盘时,该页的每个 512 字节的扇区都有一个特定的 2 位签名模式存储在数据库的页头中。从磁盘中读取页时,页头中存储的残缺位将与实际的页扇区信息进行比较。 如果值不匹配,表明只有页面的一部分被写入磁盘。如果一个页在写入持久化存储的过程中,只写了一半的页,这就是所谓的TORN_PAGE_DETECTION,SQL Server通过每个扇区提512字节中前2位作为元数据,总共16个扇区32位4字节的元数据(页头中标识为:m_tornBits),通过该元数据来检测是否存在部分写的TORN_PAGE,但该类型的页验证无法检测出页中的写入错误,因此在SQL Server 2005及以上版本,尽量选择CheckSum。 NONE:数据库页写入不会生成 CHECKSUM 或 TORN_PAGE_DETECTION 值。 在读取过程中,即使页头中存在 CHECKSUM 或 TORN_PAGE_DETECTION 值,SQL Server 也不会验证校验和或页撕裂。 当用户或系统数据库升级到 2005 SQL Server 2005 (9.x) 或更高版本时,将保留PAGE_VERIFY值 (NONE或TORN_PAGE_DETECTION) 。 强烈建议使用 CHECKSUM 校验和保护。 TORN_PAGE_DETECTION 残缺页保护可能会使用较少的资源,但提供保护的 CHECKSUM 校验和保护最小子集。 4、数据页结构 数据页包含数据行。索引页包含索引行。数据行就由行管理器来控制。而索引行,由索引管理器来负责。 而单行上的检索、修改、执行,又被事务管理器和锁管理器影响着。事务,有显性事务和隐性事务两种。而锁,又有共享锁、排它锁、更新锁、意向锁。而锁,还分为行锁、页锁、表锁、数据库锁。而锁,又有死锁的可能性。锁的不同,加上事务的影响,这个行是否能读、能修改,能怎样的读(读一致还是脏读),是等待事务和锁,还是可以进行,就受了很多影响。因为一张数据页上放的行是有限的,尤其还有填充度的影响(如填充度为80%,就这个数据页面只能填充80%就必须分页,以防以后有数据插入的时候,就非常影响数据插页,这也是性能影响比较大,尤其在插入数据比较多的情况下)。SQLSERVER的一张数据页默认是8K,除去填充度和数据头,也没有多少可存储的数据了。这就是为了关系型数据库都劝阻大家要小表大数据。也就是说,列要少,列要短,频繁访问的列要在前。数据可以海量。如果行长了,你想要检索和更新多少数据页,这需要多少页面调度,面临着页面失效和锁机制的影响。而且,大文本和可变行,都是指针存储,需要跳转查找,更浪费了不少时间。 5、表或索引的压缩选项,压缩索引时,可以使用行压缩和页压缩来压缩叶级页。 非叶级页只能使用行压缩。 DATA_COMPRESSION = {NONE | ROW | PAGE | COLUMNSTORE | COLUMNSTORE_ARCHIVE} NONE:不压缩表或指定的分区。 此选项不适用于列存储表。 ROW:使用行压缩来压缩表或指定的分区。 此选项不适用于列存储表。 PAGE:使用页压缩来压缩表或指定的分区。 此选项不适用于列存储表。 COLUMNSTORE:适用于SQL Server(SQL Server 2014 (12.x) 及更高版本)和 Azure SQL 数据库。仅适用于列存储表。 COLUMNSTORE_ARCHIVE:适用于:SQL Server(SQL Server 2014 (12.x) 及更高版本)和 Azure SQL 数据库。仅适用于列存储表。 6、没有undo文件和transaction log的备份和截断理解 1、sqlserver的undo信息记录在temp文件中和log文件中,temp文件记录事务的行版本,log文件记录事务修改动作发生之前的表的前像 2、日志备份只能截断非活动的日志,如果一个事物长时间运行,此时备份事物日志将不会引起截断发生,因为扩展分区是一个事务,该事务耗时10天,这10天内日志在不停的增加并且因为这个事务最初发生时占用的虚拟日志文件(VLM)中存在活动日志(尾日志),导致首日志(最新的活动日志序号)和尾日志(保留时间最长的活动日志序号)涉及的VLM都可能有这个事务的数据,因为VLF中存在活动日志(哪怕只有一条),所以数据库无法利用这个VLF的剩余空间。所以导致redo log日志文件越来越来大且无法收缩。 2、如果一个事物长时间运行,不管涉及多少行版本,这个事务的行版本信息都会记录在tempdb中,所以随着这个事务的时间的增加,tempdb临时文件和临时文件日志也会越来越大 7、主键和聚簇索引关系 7.1、主键默认是clustered索引,一张表无法建立两个clustered索引 create table t123 (hid int not null,hid2 int) ALTER TABLE t123 ADD PRIMARY KEY CLUSTERED (hid) --hid字段必须是not null才能创建主键 CREATE CLUSTERED INDEX [CI_hid2] ON [t123] (hid2) --无法创建有如下报错,说明创建主键没有加nonclustered时主键默认是clustered索引 报错:Cannot create more than one clustered index on table 't123'. Drop the existing clustered index 'PK__t123__DF101B01374937EF' before creating another. 7.2、创建主键时加上NONCLUSTERED,主键就是NONCLUSTERED索引 create table t123 (hid int not null,hid2 int) ALTER TABLE t123 ADD PRIMARY KEY NONCLUSTERED (hid) CREATE CLUSTERED INDEX [CI_hid2] ON [t123] (hid2) 8、聚集索引和非聚集索引的体系结构 8.1、在聚集索引中,叶节点包含基础表的数据页。 根节点和中间级节点包含存有索引行的索引页。 每个索引行包含一个键值和一个指针,该指针指向 B+ 树上的某一中间级页或叶级索引中的某个数据行。 每级索引中的页均被链接在双向链接列表中。 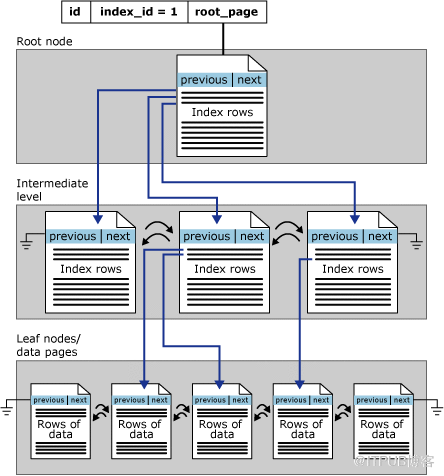 8.2、非聚集索引的叶级别是由索引页而不是由数据页组成。 非聚集索引的叶级别的索引页包含键列以及包含列。非聚集索引行中的行定位器或是指向行的指针,或是行的聚集索引键,如下所述: 如果表是堆(意味着该表没有聚集索引),则行定位器是指向行的指针。 该指针由文件标识符 (ID)、页码和页上的行数生成。 整个指针称为行 ID (RID)。 如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。 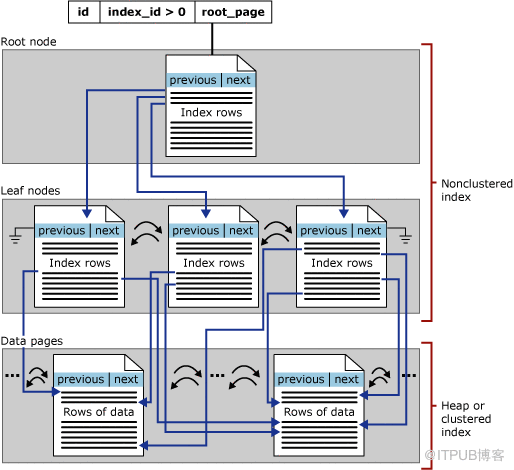 9、SQL Server锁升级的粒度,参考ALTER TABLE语句中LOCK_ESCALTATION属性 在SQL Server内存结构中,有一段是锁管理器内存。一个简单例子理解锁升级:假如一张表有1000万数据,每行数据1000bytes,Sqlserver数据页默认8KB大小,也就是一个数据页小于等于8KB/1000B=8行记录,如果对这张表执行一个select语句,数据库+架构+表+页+行上面都是共享锁。如果对这张表执行一个delete 40000行的语句,数据库+架构都是共享锁,表+页都是意向排他锁,行是排他锁,其中数据库(1个)+架构(1个)共享锁总计2个,表(1个)和页(40000行/8行=5000个)意向排他锁总计5001个,行排他锁40000个,总计1+1+5001+40000=45003个锁,每个锁消耗64+32=96Bytes的内存,这个delete 40000行的操作就要消耗锁内存45003*96/1024/1024=4.12MB的内存。当很多delete并发出现时,锁内存会大大增加,所以Sqlserver会有锁升级,一旦把行锁上升到表锁,就可以大大减少锁内存的占用,比如前面delete 30000行的例子,行锁上升到表锁后,总计3个锁=数据库(1个)共享锁+架构(1个)共享锁+表(1个)排他锁,锁内存变成288B,大大小于之前的4.12MB。 SQL Server锁升级的粒度不是从行级到页级再到表级,而是直接从行级到分区级或表级,禁用锁升级并不是最好的选项,因为SQL Server的锁管理器会消耗大量的内存 ALTER TABLE TABLENAME SET (LOCK_ESCALATION={AUTO|TABLE|DISABLE}) AUTO:借助此选项,SQL Server 数据库引擎 可选择适合于表架构的锁升级粒度。 如果该表已分区,锁升级到分区级别。 锁升级到分区级别之后,该锁以后将不会升级到TABLE粒度。 如果表未分区,锁升级到TABLE粒度。 TABLE:无论表是否已分区,锁都升级到表级粒度。 默认值为TABLE。 DISABLE:在大多数情况下禁止锁升级。 表级锁并未完全被禁止。 例如,如果扫描的表在可序列化隔离级别下没有聚集索引,数据库引擎必须使用表锁来保证数据完整性。 锁(由锁管理器维护):每个所有者 64 字节 + 32 字节 锁升级可能在以下条件之一下发生: 达到内存阈值 - 达到锁内存的40%的内存阈值。 当锁内存超过缓冲池的24%时,可以触发锁升级。 锁内存限制为可见缓冲池的60%。 锁升级阈值设置为锁内存的40%。 这是缓冲池60%中的40%,即24%。 如果锁内存超过60%的限制(如果禁用锁升级) ,则所有分配其他锁的尝试都会失败,并且1204会生成错误。 达到锁阈值 - 检查内存阈值后,评估在当前表或索引上获取的锁数。 如果该数字超过5000,则会触发锁升级。