目录
概况
- Apache Storm是Twitter开源的分布式实时计算框架。
- Storm的主要开发语言是Java和Clojure,其中Java定义骨架,Clojure编写核心逻辑。
- Storm应用(Topology):Spout是水龙头,源源不断读取消息并发送出去;Bolt是水管的每个转接口,通过Stream分组的策略转发消息流。

- Storm特性
- 易用性:只要遵循Topology、Spout和Bolt编程规范即可开发出扩展性极好的应用,无需了解底层RPC、Worker之间冗余及数据分流等。
- 容错性:守护进程(Nimbus、Supervisor等)是无状态的,状态保存在ZooKeeper可随意重启;Worker失效或机器故障时,Storm自动分配新Worker替换失效Worker。
- 伸缩性:可线性伸缩。
- 完整性:采用Acker机制,保证数据不丢失;采用事务机制,保证数据准确性。
- Storm应用方向
- 流处理(Stream Processing):最基本的应用,Storm处理源源不断流进来的消息,处理后将结果写到某存储。
- 连续计算(Continuous Computation):Storm保证计算永远运行,直到用户结束计算进程。
- 分布式RPC(Distributed RPC):可作为分布式RPC框架使用。
- 与Spark Streaming比较
- 联合历史数据:Spark Streaming将流数据分成小的时间片段(几秒到几分钟),以类似batch批量处理的方式处理这些小部分数据,因此可同时兼容批量和实时数据处理的逻辑和算法,便于历史数据和实时数据联合分析。
- 延迟:Storm处理每次传入的一个事件,Spark Streaming处理某个时间段窗口内的事件流,因此Storm延迟极低,Spark Streaming相对较高。
手工搭建集群
引言
- 环境:
| Role | Host name |
|---|---|
| Nimbus | centos1 |
| Supervisor | centos2 |
| Supervisor | centos3 |
- 假设已成功安装JDK、ZooKeeper集群。
安装Python
-
[Nimbus、Supervisor]登录root用户安装Python到/usr/local/python目录下。
tar zxvf Python-2.7.13.tgz # Ubuntu要先安装依赖sudo apt-get install build-essential zlib1g-dev cd Python-2.7.13/ ./configure --prefix=/usr/local/python make sudo make install -
[Nimbus、Supervisor]配置命令。
ln -s /usr/local/python/bin/python /usr/bin/python # 软链接 python -V # 验证
配置文件
-
[Nimbus]
cd tar zxvf apache-storm-1.1.0.tar.gz -C /opt/app cd /opt/app/apache-storm-1.1.0 vi conf/storm.yamlstorm.zookeeper.servers: - "centos1" - "centos2" storm.zookeeper.port: 2181 nimbus.seeds: ["centos1"] supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 storm.local.dir: "/opt/app/storm.local.dir" ui.port: 8080 -
[Nimbus]从Nimbus复制Storm目录到各Supervisor。
scp -r /opt/app/apache-storm-1.1.0 hadoop@centos2:/opt/app scp -r /opt/app/apache-storm-1.1.0 hadoop@centos3:/opt/app
启动与测试
-
[Nimbus、Supervisor]配置Storm环境变量。
export STORM_HOME=/opt/app/apache-storm-1.1.0 export PATH=$PATH:$STORM_HOME/bin -
[Nimbus]启动守护进程。
nohup bin/storm nimbus 1>/dev/null 2>&1 & nohup bin/storm ui 1>/dev/null 2>&1 & nohup bin/storm logviewer 1>/dev/null 2>&1 & jpsnimbus # Nimbus守护进程 core # Storm UI守护进程 logviewer # LogViewer守护进程 -
[Supervisor]启动守护进程。
nohup bin/storm supervisor 1>/dev/null 2>&1 & nohup bin/storm logviewer 1>/dev/null 2>&1 & jpssupervisor # Supervisor守护进程 logviewer # LogViewer守护进程 -
[Nimbus]测试。
storm jar teststorm.jar teststorm.WordCountTopology wordcount -
监控页面。
http://centos1:8080 # Storm UI -
[Nimbus]关闭守护进程。
kill -s TERM ${PID} # PID为各守护进程ID
应用部署
参数配置
- 配置方式
- External Component Specific Configuration:通过TopologyBuilder的setSpout和setBold方法返回的SpoutDeclarer和BoldDeclarer对象的一系列方法。
- Internal Component Specific Configuration:Override Spout和Bold的getComponentConfiguration方法并返回Map。
- Topology Specific Configuration:命令传参“bin/storm -c conf1=v1 -c conf2=v2”。
- storm.yaml:“$STORM_HOME/conf/storm.yaml”。
- defaults.yaml:“$STORM_HOME/lib/storm-core-x.y.z.jar/defaults.yaml”。
- 参数优先级:
defaults.yaml
< storm.yaml
< Topology Specific Configuration
< Internal Component Specific Configuration
< External Component Specific Configuration
Storm命令
常用命令,详情参考官方文档。
storm jar topology-jar-path class ...
storm kill topology-name [-w wait-time-secs]
storm activate topology-name
storm deactivate topology-name
storm rebalance topology-name [-w wait-time-secs] [-n new-num-workers] [-e component=parallelism]*
storm classpath
storm localconfvalue conf-name
storm remoteconfvalue conf-name
storm nimbus
storm supervisor
storm ui
storm get-errors topology-name
storm kill_workers
storm list
storm logviewer
storm set_log_level -l [logger name]=[log level][:optional timeout] -r [logger name] topology-name
storm version
storm help [command]原理
Storm架构

Storm组件
| 名称 | 说明 |
|---|---|
| Nimbus | 负责资源分配和任务调度,类似Hadoop的JobTracker。 |
| Supervisor | 负责接受Nimbus分配的任务,启动和停止属于自己管理的Worker进程,类似Hadoop的TaskTracker。 |
| Worker | 运行具体处理组件逻辑的进程。 |
| Executor | Executor为Worker进程中具体的物理线程,同一个Spout/Bolt的Task可能会共享一个物理线程,一个Executor中只能运行隶属于同一个Spout/Bolt的Task。 |
| Task | 每一个Spout/Bolt具体要做的工作,也是各节点之间进行分组的单位。 |
| Topology | 一个实时计算应用程序逻辑上被封装在Topology对象中,类似Hadoop的作业。与作业不同的是,Topology会一直运行直到显式被杀死。 |
| Spout | a) 在Topology中产生源数据流。b) 通常Spout获取数据源的数据(如MQ),然后调用nextTuple方法,发射数据供Bolt消费。c) 可通过OutputFieldsDeclarer的declareStream方法声明1或多个流,并通过OutputCollector的emit方法向指定流发射数据。 |
| Bolt | a) 在Topology中接受Spout的数据并执行处理。b) 当处理复杂逻辑时,可分成多个Bolt处理。c) Bolt在接受到消息后调用execute方法,在此可执行过滤、合并、写数据库等操作。d) 可通过OutputFieldsDeclarer的declareStream方法声明1或多个流,并通过OutputCollector的emit方法向指定流发射数据。 |
| Tuple | 消息传递的基本单元。 |
| Stream | 源源不断传递的Tuple组成了Stream |
| Stream Grouping | 即消息的分区(partition),内置了7种分组策略。 |
Stream Grouping
- Stream Grouping定义了数据流在Bolt间如何被切分。
- 内置7种Stream Grouping策略
- Shuffle grouping:随机分组,保证各Bolt接受的Tuple数量一致。
- Fields grouping:根据Tuple中某一个或多个字段分组,相同分组字段的Tuple发送至同一Bolt。
- All grouping:数据流被复制发送给所有Bolt,慎用。
- Global grouping:整个数据流只发给ID值最小的Bolt。
- None grouping:不关心如何分组,当前与Shuffle grouping相同。
- Direct grouping:生产Tuple的Spout/Bolt指定该Tuple的消费者Bolt。通过OutputCollector的emitDirect方法实现。
- Local or shuffle grouping:如果目标Bolt有一个或多个Task与当前生产Tuple的Task在同一Worker进程,那么将该Tuple发送给该目标Bolt;否则Shuffle grouping。
- 自定义Stream Grouping策略:实现CustomStreamGrouping接口。
守护进程容错性(Daemon Fault Tolerance)
- Worker:如果Worker故障,则Supervisor重启该Worker;如果其仍然故障,则Nimbus重新分配Worker资源。
- 节点:如果节点机器故障,则该节点上的Task将超时,Nimbus将这些Task分配到其他节点。
- Nimbus和Supervisor:Nimbus和Supervisor都是fail-fast(故障时进程自销毁)和stateless(状态保存在ZooKeeper或磁盘),故障后重启进程即可;Worker进程不会受Nimbus或Supervisor故障影响,但Worker进程的跨节点迁移会受影响。
- Nimbus:Storm v1.0.0开始引入Nimbus HA。
数据可靠性(Guaranteeing Message Processing)
- MessageId:Storm允许用户在Spout发射新Tuple时为其指定MessageId(Object类型);多个Tuple可共用同一MessageId,表示它们是同一消息单元。
- 可靠性:Tuple超时时间内,该MessageId绑定的Stream Tuple及其衍生的所有Tuple都已经过Topology中应该到达的Bolt处理;Storm使用Acker解决Tuple消息可靠性问题(调用OutputCollector的ack和fail方法告知Storm该Tuple处理成功和失败)。
- Tuple超时时间:通过参数“topology.message.timeout.secs”配置,默认30秒。
- 锚定(Anchoring)
- Tuple从Spout到Bolt形成了Tuple tree,以WordCount为例:

- 锚定:Tuple被锚定后,如果Tuple未被下游ack,根节点的Spout将稍后重发Tuple。
- 锚定的API写法:
- Tuple从Spout到Bolt形成了Tuple tree,以WordCount为例:
// Spout
collector.emit(new Values(content1), uniqueMessageId);// Bold
collector.emit(tuple, new Values(content2));
collector.ack(tuple);* 未锚定:Tuple未被锚定,如果Tuple未被下游ack,根节点的Spout不会重发Tuple。
* 未锚定的API写法:// Bold
collector.emit(new Values(content));
collector.ack(tuple);* 复合锚定:一个输出Tuple可被锚定到多个输入Tuple。复合锚定会打破树结构,形成有向无环图(DAG)。
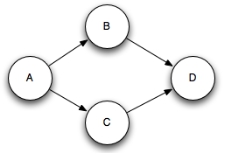
* 复合锚定API写法:// Bold
List<Tuple> anchors = new ArrayList<>();
anchors.add(tuple1);
anchors.add(tuple2);
collector.emit(anchors, new Values(content));
collector.ack(tuple);* ack和fail:每一个Tuple必须执行ack或fail,Storm使用内存跟踪每个Tuple,如果未ack或fail,任务最终会内存耗尽。
* Acker任务:Topology有一组特殊的Acker任务跟踪Tuple树或有向无环图,通过参数“topology.acker.executors”或“Config.TOPOLOGY_ACKER_EXECUTORS”配置Acker任务数量,默认为1。处理量大时应增大该值。- 关闭可靠性:如果对可靠性要求不高,可关闭以提高性能。
- 方法1:设置“Config.TOPOLOGY_ACKER_EXECUTORS”为0。
- 方法2:采用未锚定的API写法写法。
消息传输机制
自Storm 0.9.0开始使用Netty作为消息通信解决方案,已不再需要ZeroMQ。
API
WordCount示例
- WordCountTopology.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class WordCountTopology {
private static final Logger logger = LoggerFactory.getLogger(WordCountTopology.class);
public static void main(String[] args) throws InterruptedException {
final String inputFile = "/opt/app/apache-storm-1.1.0/LICENSE";
final String outputDir = "/opt/workspace/wordcount";
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(FileReadSpout.class.getSimpleName(), new FileReadSpout(inputFile));
builder.setBolt(LineSplitBolt.class.getSimpleName(), new LineSplitBolt())
.shuffleGrouping(FileReadSpout.class.getSimpleName());
// 最终生成4个文件
builder.setBolt(WordCountBolt.class.getSimpleName(), new WordCountBolt(outputDir), 2)
.setNumTasks(4)
.fieldsGrouping(LineSplitBolt.class.getSimpleName(), new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
logger.error("Failed to submit " + WordCountTopology.class.getName() + ".", e);
}
} else {
conf.setDebug(true);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(WordCountTopology.class.getSimpleName(), conf, builder.createTopology());
Thread.sleep(30 * 1000);
cluster.shutdown();
}
}
}- FileReadSpout.java
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
public class FileReadSpout extends BaseRichSpout {
private static final long serialVersionUID = 8543601286964250940L;
private String inputFile;
private BufferedReader reader;
private SpoutOutputCollector collector;
public FileReadSpout(String inputFile) {
this.inputFile = inputFile;
}
@Override
@SuppressWarnings("rawtypes")
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
try {
reader = new BufferedReader(new FileReader(inputFile));
} catch (FileNotFoundException e) {
throw new RuntimeException("Cannot find file [" + inputFile + "].", e);
}
this.collector = collector;
}
@Override
public void nextTuple() {
try {
String line = null;
while ((line = reader.readLine()) != null) {
collector.emit(new Values(line));
}
} catch (IOException e) {
throw new RuntimeException("Encountered a file read error.", e);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
@Override
public void close() {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
// Ignore
}
}
super.close();
}
}- LineSplitBolt.java
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class LineSplitBolt extends BaseRichBolt {
private static final long serialVersionUID = -2045688041930588092L;
private OutputCollector collector;
@Override
@SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String line = tuple.getStringByField("line");
String[] words = line.split(" ");
for (String word : words) {
word = word.trim();
if (!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word, 1));
}
}
collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
@Override
public void cleanup() {
super.cleanup();
}
}- WordCountBolt.java
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class WordCountBolt extends BaseRichBolt {
private static final long serialVersionUID = 8239697869626573368L;
private static final Logger logger = LoggerFactory.getLogger(WordCountBolt.class);
private String outputDir;
private OutputCollector collector;
private Map<String, Integer> wordCounter;
public WordCountBolt(String outputDir) {
this.outputDir = outputDir;
}
@Override
@SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
wordCounter = new HashMap<>();
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Integer count = tuple.getIntegerByField("count");
Integer wordCount = wordCounter.get(word);
if (wordCount == null) {
wordCounter.put(word, count);
} else {
wordCounter.put(word, count + wordCount);
}
collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
if (wordCounter != null) {
outputResult(wordCounter);
wordCounter.clear();
}
super.cleanup();
}
private void outputResult(Map<String, Integer> wordCounter) {
String filePath = outputDir + "/" + UUID.randomUUID().toString();
RandomAccessFile randomAccessFile = null;
try {
randomAccessFile = new RandomAccessFile(filePath, "rw");
for (Map.Entry<String, Integer> entry : wordCounter.entrySet()) {
randomAccessFile.writeChars(entry.getKey());
randomAccessFile.writeChar('\t');
randomAccessFile.writeChars(String.valueOf(entry.getValue()));
randomAccessFile.writeChar('\n');
}
} catch (IOException e) {
logger.error("Failed to write file [" + filePath + "].", e);
} finally {
if (randomAccessFile != null) {
try {
randomAccessFile.close();
} catch (IOException e) {
logger.warn("Failed to close output stream.", e);
}
}
}
}
}应用部署方式
应用程序部署(Topology提交)分类
* 本地模式:在进程中模拟Storm集群,用于开发、测试。
* 集群模式:用于生产。
组件接口
- IComponent
package org.apache.storm.topology;
import java.io.Serializable;
import java.util.Map;
/**
* Common methods for all possible components in a topology. This interface is used
* when defining topologies using the Java API.
*/
public interface IComponent extends Serializable {
/**
* Declare the output schema for all the streams of this topology.
*
* @param declarer this is used to declare output stream ids, output fields, and whether or not each output stream is a direct stream
*/
void declareOutputFields(OutputFieldsDeclarer declarer);
/**
* Declare configuration specific to this component. Only a subset of the "topology.*" configs can
* be overridden. The component configuration can be further overridden when constructing the
* topology using {@link TopologyBuilder}
*
*/
Map<String, Object> getComponentConfiguration();
}- ISpout
package org.apache.storm.spout;
import org.apache.storm.task.TopologyContext;
import java.util.Map;
import java.io.Serializable;
/**
* ISpout is the core interface for implementing spouts. A Spout is responsible
* for feeding messages into the topology for processing. For every tuple emitted by
* a spout, Storm will track the (potentially very large) DAG of tuples generated
* based on a tuple emitted by the spout. When Storm detects that every tuple in
* that DAG has been successfully processed, it will send an ack message to the Spout.
*
* If a tuple fails to be fully processed within the configured timeout for the
* topology (see {@link org.apache.storm.Config}), Storm will send a fail message to the spout
* for the message.
*
* When a Spout emits a tuple, it can tag the tuple with a message id. The message id
* can be any type. When Storm acks or fails a message, it will pass back to the
* spout the same message id to identify which tuple it's referring to. If the spout leaves out
* the message id, or sets it to null, then Storm will not track the message and the spout
* will not receive any ack or fail callbacks for the message.
*
* Storm executes ack, fail, and nextTuple all on the same thread. This means that an implementor
* of an ISpout does not need to worry about concurrency issues between those methods. However, it
* also means that an implementor must ensure that nextTuple is non-blocking: otherwise
* the method could block acks and fails that are pending to be processed.
*/
public interface ISpout extends Serializable {
/**
* Called when a task for this component is initialized within a worker on the cluster.
* It provides the spout with the environment in which the spout executes.
*
* This includes the:
*
* @param conf The Storm configuration for this spout. This is the configuration provided to the topology merged in with cluster configuration on this machine.
* @param context This object can be used to get information about this task's place within the topology, including the task id and component id of this task, input and output information, etc.
* @param collector The collector is used to emit tuples from this spout. Tuples can be emitted at any time, including the open and close methods. The collector is thread-safe and should be saved as an instance variable of this spout object.
*/
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
/**
* Called when an ISpout is going to be shutdown. There is no guarentee that close
* will be called, because the supervisor kill -9's worker processes on the cluster.
*
* The one context where close is guaranteed to be called is a topology is
* killed when running Storm in local mode.
*/
void close();
/**
* Called when a spout has been activated out of a deactivated mode.
* nextTuple will be called on this spout soon. A spout can become activated
* after having been deactivated when the topology is manipulated using the
* `storm` client.
*/
void activate();
/**
* Called when a spout has been deactivated. nextTuple will not be called while
* a spout is deactivated. The spout may or may not be reactivated in the future.
*/
void deactivate();
/**
* When this method is called, Storm is requesting that the Spout emit tuples to the
* output collector. This method should be non-blocking, so if the Spout has no tuples
* to emit, this method should return. nextTuple, ack, and fail are all called in a tight
* loop in a single thread in the spout task. When there are no tuples to emit, it is courteous
* to have nextTuple sleep for a short amount of time (like a single millisecond)
* so as not to waste too much CPU.
*/
void nextTuple();
/**
* Storm has determined that the tuple emitted by this spout with the msgId identifier
* has been fully processed. Typically, an implementation of this method will take that
* message off the queue and prevent it from being replayed.
*/
void ack(Object msgId);
/**
* The tuple emitted by this spout with the msgId identifier has failed to be
* fully processed. Typically, an implementation of this method will put that
* message back on the queue to be replayed at a later time.
*/
void fail(Object msgId);
}- IBolt
package org.apache.storm.task;
import org.apache.storm.tuple.Tuple;
import java.util.Map;
import java.io.Serializable;
/**
* An IBolt represents a component that takes tuples as input and produces tuples
* as output. An IBolt can do everything from filtering to joining to functions
* to aggregations. It does not have to process a tuple immediately and may
* hold onto tuples to process later.
*
* A bolt's lifecycle is as follows:
*
* IBolt object created on client machine. The IBolt is serialized into the topology
* (using Java serialization) and submitted to the master machine of the cluster (Nimbus).
* Nimbus then launches workers which deserialize the object, call prepare on it, and then
* start processing tuples.
*
* If you want to parameterize an IBolt, you should set the parameters through its
* constructor and save the parameterization state as instance variables (which will
* then get serialized and shipped to every task executing this bolt across the cluster).
*
* When defining bolts in Java, you should use the IRichBolt interface which adds
* necessary methods for using the Java TopologyBuilder API.
*/
public interface IBolt extends Serializable {
/**
* Called when a task for this component is initialized within a worker on the cluster.
* It provides the bolt with the environment in which the bolt executes.
*
* This includes the:
*
* @param stormConf The Storm configuration for this bolt. This is the configuration provided to the topology merged in with cluster configuration on this machine.
* @param context This object can be used to get information about this task's place within the topology, including the task id and component id of this task, input and output information, etc.
* @param collector The collector is used to emit tuples from this bolt. Tuples can be emitted at any time, including the prepare and cleanup methods. The collector is thread-safe and should be saved as an instance variable of this bolt object.
*/
void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
/**
* Process a single tuple of input. The Tuple object contains metadata on it
* about which component/stream/task it came from. The values of the Tuple can
* be accessed using Tuple#getValue. The IBolt does not have to process the Tuple
* immediately. It is perfectly fine to hang onto a tuple and process it later
* (for instance, to do an aggregation or join).
*
* Tuples should be emitted using the OutputCollector provided through the prepare method.
* It is required that all input tuples are acked or failed at some point using the OutputCollector.
* Otherwise, Storm will be unable to determine when tuples coming off the spouts
* have been completed.
*
* For the common case of acking an input tuple at the end of the execute method,
* see IBasicBolt which automates this.
*
* @param input The input tuple to be processed.
*/
void execute(Tuple input);
/**
* Called when an IBolt is going to be shutdown. There is no guarentee that cleanup
* will be called, because the supervisor kill -9's worker processes on the cluster.
*
* The one context where cleanup is guaranteed to be called is when a topology
* is killed when running Storm in local mode.
*/
void cleanup();
}- IRichSpout
package org.apache.storm.topology;
import org.apache.storm.spout.ISpout;
/**
* When writing topologies using Java, {@link IRichBolt} and {@link IRichSpout} are the main interfaces
* to use to implement components of the topology.
*
*/
public interface IRichSpout extends ISpout, IComponent {
}- IRichBolt
package org.apache.storm.topology;
import org.apache.storm.task.IBolt;
/**
* When writing topologies using Java, {@link IRichBolt} and {@link IRichSpout} are the main interfaces
* to use to implement components of the topology.
*
*/
public interface IRichBolt extends IBolt, IComponent {
}- IBasicBolt
package org.apache.storm.topology;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.tuple.Tuple;
import java.util.Map;
public interface IBasicBolt extends IComponent {
void prepare(Map stormConf, TopologyContext context);
/**
* Process the input tuple and optionally emit new tuples based on the input tuple.
*
* All acking is managed for you. Throw a FailedException if you want to fail the tuple.
*/
void execute(Tuple input, BasicOutputCollector collector);
void cleanup();
}- IStateSpout(Storm内部未完成)
package org.apache.storm.state;
import org.apache.storm.task.TopologyContext;
import java.io.Serializable;
import java.util.Map;
public interface IStateSpout extends Serializable {
void open(Map conf, TopologyContext context);
void close();
void nextTuple(StateSpoutOutputCollector collector);
void synchronize(SynchronizeOutputCollector collector);
}- IRichStateSpout(Storm内部未完成)
package org.apache.storm.topology;
import org.apache.storm.state.IStateSpout;
public interface IRichStateSpout extends IStateSpout, IComponent {
}组件实现类
- BaseComponent
package org.apache.storm.topology.base;
import org.apache.storm.topology.IComponent;
import java.util.Map;
public abstract class BaseComponent implements IComponent {
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}- BaseRichSpout
package org.apache.storm.topology.base;
import org.apache.storm.topology.IRichSpout;
public abstract class BaseRichSpout extends BaseComponent implements IRichSpout {
@Override
public void close() {
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void ack(Object msgId) {
}
@Override
public void fail(Object msgId) {
}
}- BaseRichBolt
package org.apache.storm.topology.base;
import org.apache.storm.topology.IRichBolt;
public abstract class BaseRichBolt extends BaseComponent implements IRichBolt {
@Override
public void cleanup() {
}
}- BaseBasicBolt
package org.apache.storm.topology.base;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IBasicBolt;
import java.util.Map;
public abstract class BaseBasicBolt extends BaseComponent implements IBasicBolt {
@Override
public void prepare(Map stormConf, TopologyContext context) {
}
@Override
public void cleanup() {
}
}数据连接方式
- 直接连接(Direct Connection)
- 场景:特别适合消息发射器是已知设备或设备组的场景。已知设备指在Topology启动时已知并在Topology生命周期中保持不变的设备。对于变化的设备可协调器通知Topology创建新Spout连接。
- 直接连接架构图

- 设备组直接连接架构图

- 基于协调器的直接连接

- 消息队列(Enqueued Messages)

常用Topology模式
- BasicBolt
- 含义:Storm自动在Bolt的execute方法后ack输入的Tuple。
- 方法:实现org.apache.storm.topology.IBasicBolt接口。
- 流连接(Stream Join)
- 含义:基于某些字段,把两个或更多数据流结合到一起,形成一个新的数据流。
- 方法:
builder.setBolt("join", new Joiner(), parallelism)
.fieldGrouping("1", new Field("1-joinfield1", "1-joinfield2"))
.fieldGrouping("2", new Field("2-joinfield1", "2-joinfield2"))
.fieldGrouping("3", new Field("3-joinfield1", "3-joinfield2"));- 批处理(Batching)
- 含义:对一组Tuple处理而不是单个处理。
- 方法:在Bolt成员变量保存Tuple引用以便批处理,处理完成后,ack该批Tuple。
- TopN
- 含义:按照某个统计指标(如出现次数)计算TopN,然后每隔一段时间输出TopN结果。例如微博的热门话题、热门点击图片。
- 方法:为处理大数据量的流,可先由多个Bolt并行计算TopN,再合并结果到一个Bolt计算全局TopN。
builder.setBolt("rank", new RankBolt(), parallelism)
.fieldGrouping("spout", new Fields("count"));
builder.setBolt("merge_rank", new MergeRank())
.globalGrouping("rank");日志(集群模式)
- 提交日志:“$STORM_HOME/logs/nimbus.log”。
- 运行日志
- 设置日志:Storm UI或“$STORM_HOME/logback/cluster.xml”。
- 查看日志:Storm UI或各节点的“$STORM_HOME/logs/worker-port.log”(port为具体数字)。
- 日志框架冲突:Storm使用logback日志框架,logback和log4j作为两套slf4j的实现不可共存,应在Maven中剔除其他框架引入的log4j:
<dependency>
<groupId>...</groupId>
<artifactId>...</artifactId>
<version>...</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
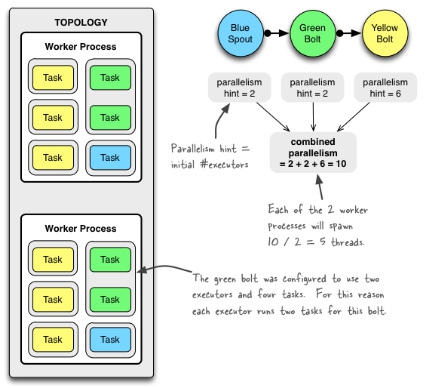
</dependency>并行度设置
- 组件与并行度关系:
- 一个运行的Topology由集群中各机器运行的多个Worker进程组成,一个Worker进程仅属于一个Topology;
- 一个Worker进程中包含一或多个Executor线程;
- 一个Executor线程中包含一或多个Task,Task是Spout或Bolt;
- 默认,一个Executor对应一个Task。
- 示例
- 代码(提交时设置并行度)
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);* 并行度:mytopology总共包含2个Worker进程、10个Executor线程(2个blue-spout + 2个green-bolt + 6个yellow-bolt)、12个Task(2个blue-spout + 4个green-bolt + 6个yellow-bolt),其中2个green-bolt Executor各运行2个Bolt Task。
* 运行时修改并行度:重新设置为5个Worker进程、3个blue-spout Executor、10个yellow-bolt Executor。storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10tick定时机制
- 场景:定时处理某些业务逻辑,例如每5分钟统计一次并将结果保存到数据库。
- 原理:让Topology的系统组件定时发送tick消息,Bolt接收到tick消息后,触发相应的业务逻辑。
- 代码:修改WordCount代码,定时5秒输出一次。
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import org.apache.storm.Config;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.utils.TupleUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class WordCountBolt extends BaseRichBolt {
private static final long serialVersionUID = 8239697869626573368L;
private static final Logger logger = LoggerFactory.getLogger(WordCountBolt.class);
private String outputDir;
private OutputCollector collector;
private Map<String, Integer> wordCounter;
public WordCountBolt(String outputDir) {
this.outputDir = outputDir;
}
@Override
@SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
wordCounter = new HashMap<>();
}
@Override
public void execute(Tuple tuple) {
if (TupleUtils.isTick(tuple)) { // tick tuple
outputResult(wordCounter);
wordCounter.clear();
} else { // 正常tuple
String word = tuple.getStringByField("word");
Integer count = tuple.getIntegerByField("count");
Integer wordCount = wordCounter.get(word);
if (wordCount == null) {
wordCounter.put(word, count);
} else {
wordCounter.put(word, count + wordCount);
}
}
collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
if (wordCounter != null) {
wordCounter.clear();
}
super.cleanup();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config conf = new Config();
// 5秒定时
conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 5);
return conf;
}
private void outputResult(Map<String, Integer> wordCounter) {
String filePath = outputDir + "/" + UUID.randomUUID().toString();
RandomAccessFile randomAccessFile = null;
try {
randomAccessFile = new RandomAccessFile(filePath, "rw");
for (Map.Entry<String, Integer> entry : wordCounter.entrySet()) {
randomAccessFile.writeChars(entry.getKey());
randomAccessFile.writeChar('\t');
randomAccessFile.writeChars(String.valueOf(entry.getValue()));
randomAccessFile.writeChar('\n');
}
} catch (IOException e) {
logger.error("Failed to write file [" + filePath + "].", e);
} finally {
if (randomAccessFile != null) {
try {
randomAccessFile.close();
} catch (IOException e) {
logger.warn("Failed to close output stream.", e);
}
}
}
}
}序列化
- 用途:Storm是一个分布式系统,Tuple对象在任务之间传递时需序列化和反序列化。
- 支持类型:
- Java基本类型
- String
- byte[]
- ArrayList
- HashMap
- HashSet
- Clojure集合
- 自定义序列化
- 序列化框架:Kryo,灵活、快速。
- 序列化方式:动态类型,即无需为Tuple中的字段声明类型。
- 自定义序列化:需要时参考官方文档。
- 未知类型序列化
- Storm使用Java序列化处理没有序列化注册的类,如果无法序列化,则抛出异常。
- 可配置参数“topology.fall.back.on.java.serialization”为false关闭Java序列化。
与其他系统集成
Storm已封装与以下系统集成的API,需要时参考官方文档。
- Apache Kafka
- Apache HBase
- Apache HDFS
- Apache Hive
- Apache Solr
- Apache Cassandra
- JDBC
- JMS
- Redis
- Event Hubs
- Elasticsearch
- MQTT
- Mongodb
- OpenTSDB
- Kinesis
- Druid
- Kestrel
性能调优
- 不要在Spout处理耗时操作
- 背景:Spout是单线程的,启用Ack时,在该线程同时执行Spout的nextTuple、ack和fail方法(JStorm启动3个线程分别执行这3个方法)。
- 如果nextTuple方法非常耗时,Acker给Spout发送Tuple执行ack或fail方法无法及时相应,可能造成ACK超时后被丢弃,Spout反而认为该Tuple执行失败。
- 如果ack或fail方法非常耗时,会影响Spout执行nextTuple方法发射数据量,造成Topology吞吐量降低。
- 注意Fields grouping数据均衡性
如果按某分组字段分组后的数据,某些分组字段对应的数据非常多,另一些非常少,那么会造成下一级Bolt收到的数据不均衡,整个性能将受制于那些数据量非常大的节点。 - 优先使用Local or shuffle grouping
- 原理:使用Local or shuffle grouping时,在Worker内部传输,只需通过Disruptor队列完成,无网络开销和序列化开销。
- 结论:数据处理复杂度不高而网络和序列化开销占主要时,使用Local or shuffle grouping代替Shuffle grouping。
- 合理设置MaxSpoutPending
- 背景:启用Ack时,Spout将已发射但未等到Ack的Tuple保存在RotatingMap。
- 设置方式:通过参数“topology.max.spout.pending”或TopologyBuilder.setSout.setMaxSpoutPending方法设置其最大个数。
- 方法:具体优化值再参考资料。
- Netty优化
| 参数 | 默认值(defaults.yaml) |
|---|---|
| storm.messaging.transport | org.apache.storm.messaging.netty.Context |
| storm.messaging.netty.server_worker_threads | 1 |
| storm.messaging.netty.client_worker_threads | 1 |
| storm.messaging.netty.buffer_size | 5242880 |
| storm.messaging.netty.transfer.batch.size | 262144 |
- JVM调优
- 参数“worker.childopts”,例如:
work.childopts: "-Xms2g -Xmx2g"